Design a RAG System
You’re asked to build and deploy a Retrieval-Augmented Generation (RAG) service for document conversations.
The system’s core purpose is to retrieve the most relevant internal documents in real time and generate concise, accurate responses based on that context, all while handling large volumes of data efficiently.
As usual, we'll design this system following our PADME framework. Let's go!
Problem Definition
A RAG system is basically a chatbot that has access to some additional information, such as company documents, an internal database, real-time data, or some other user-provided documents (e.g. uploaded PDFs). RAG has become very popular as of late, Just explore some seed round companies!* with the most popular examples being Perplexity, glean or on the open-source side, LlamaIndex.
Clarifying Questions
Some questions relevant to a RAG system include:
- What languages will the system support? English text only for simplicity.
- Which modalities (text, images, audio) should the system handle? Primarily text documents, with potential for basic image/chart extraction from PDFs.
- Are there constraints around content moderation or privacy? Yes, strict privacy for internal documents and content safety filtering required.
- How large and dynamic is the data set? Large-scale (millions of documents) with periodic updates rather than real-time changes.
- What latency expectations are there for retrieval and generation processes? Sub-second retrieval with total response time under 3-5 seconds.
- What types of documents will the system index - structured data, unstructured PDFs, emails, or mixed formats? Mixed formats including PDFs, Word docs, and internal wikis/documentation.
- Should the system provide source citations and confidence scores with responses? Yes, citation tracking and confidence indicators are essential for enterprise use.
- Do we need to handle different user access levels or document permissions? Yes, respect existing document access controls and user permissions.
- What's the expected query complexity - simple facts, multi-step reasoning, or summarization tasks? Mix of factual lookups and complex multi-document synthesis questions.
- Should responses be personalized based on user role, department, or query history? Basic role-based filtering, but no deep personalization initially.
Great, so we assume the RAG system supports English text only, requires real-time retrieval, handles large-scale internal documents, maintains strict privacy and safety standards, and provides cited responses with appropriate access controls. Pretty standard stuff you should expect in an interview.
Business Objectives
Typically, the business objectives for a RAG system relate to enhancing information accessibility and accuracy in response generation for some core product or internal service. Specific objectives may include: Basically every company these days has a few RAG products in flight, whether internal or external. This is a good place to learn more about the companies current generative ai efforts.*
- Improving customer service efficiency by enabling accurate, immediate responses.
- Reducing operational costs by automating complex query handling.
- Increasing user satisfaction through fast and contextually accurate interactions.
ML Task
The ML task for this question is very straightforward - we're literally asked to design a specific ML System centered around combining retrieval methods with generative language models: You may be asked to design e.g. a chatbot for internal documents instead, in which case everything would still be identical, minus the step of mentioning "use RAG."*
- Task type: Retrieval-augmented generation, combining information retrieval with generative models.
- Model inputs: User queries, indexed internal documents.
- Model outputs: Generated textual responses supported by relevant retrieved documents.
- Key considerations: Managing high-volume real-time retrieval, ensuring generated responses remain accurate and faithful to retrieved content.
Success Criteria
When we discuss the success criteria for a RAG system, we'll need to touch multiple aspects of the service. Remember, we're just outlining them here (we'll go in towards the end of the interview):
- Retrieval metrics: Hit Rate@K, Mean Reciprocal Rank (MRR).
- Generation metrics: Time to First Token (TTFT), accuracy and faithfulness of generated answers.
- System metrics: Index freshness, throughput capabilities.
- User-centric metrics: Session depth, escalation rate (the frequency with which users seek human intervention).
Approach Outline
Recall that a RAG system combines real-time retrieval with a general-purpose LLM. The main idea is that a pretrained LLM is not sufficient, so augmenting the generative model with documents via a retrieval service will provide for more accurate and relevant responses, alongside the ability to cite and fact-check, if needed.
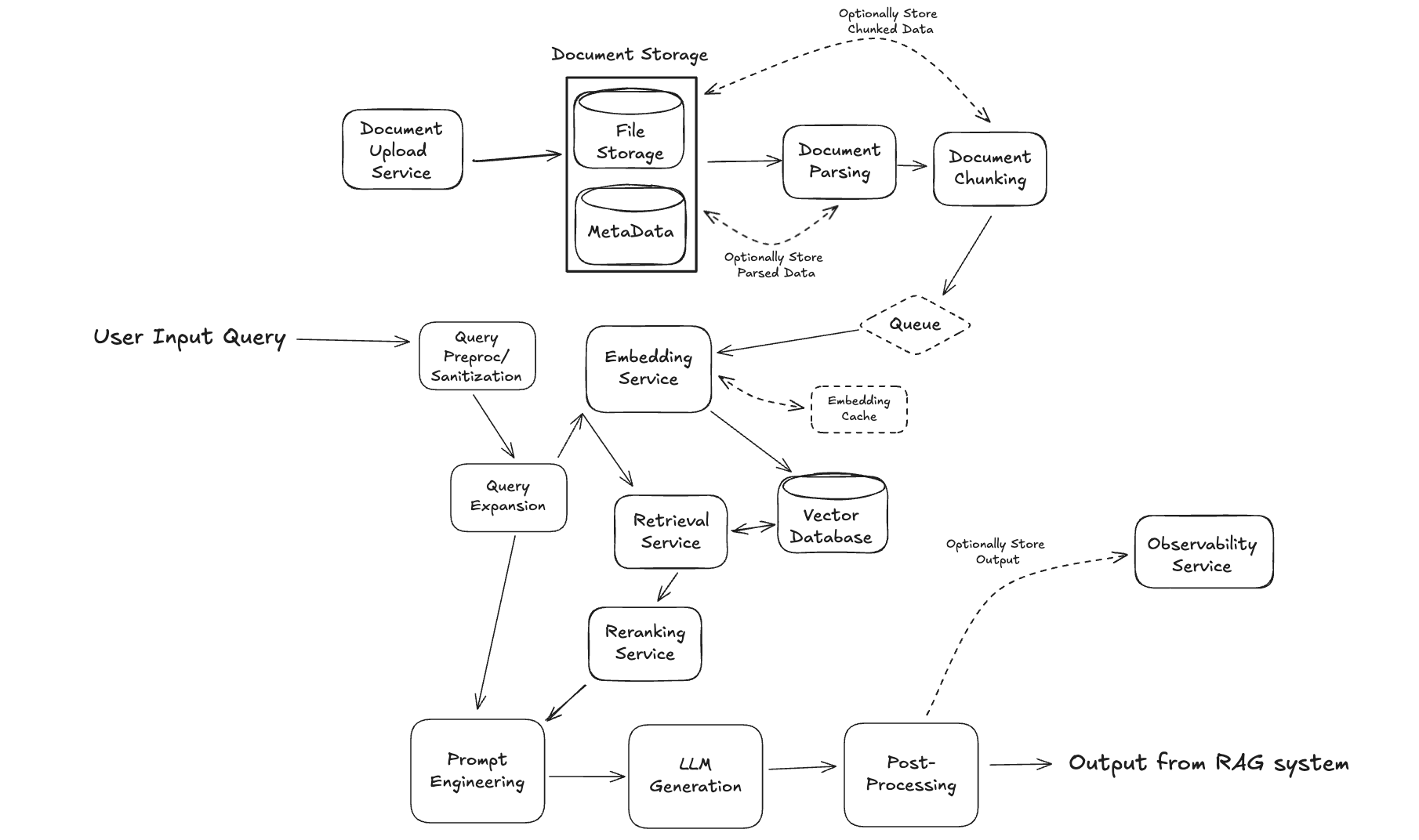
Given that the retrieval augments the generation, it should come as no surprise that the two core components to a RAG system are, drumroll, Retrieval and Generation. The Retrieval component is in charge of identifying the most relevant indexed documents to a given user's input. While the Generation component is responsible for generating a response based on the user's input that makes use of the retrieved documents. In addition, a third core component is the Data component to handle documents. As a starting point, you can begin outlining the RAG system:
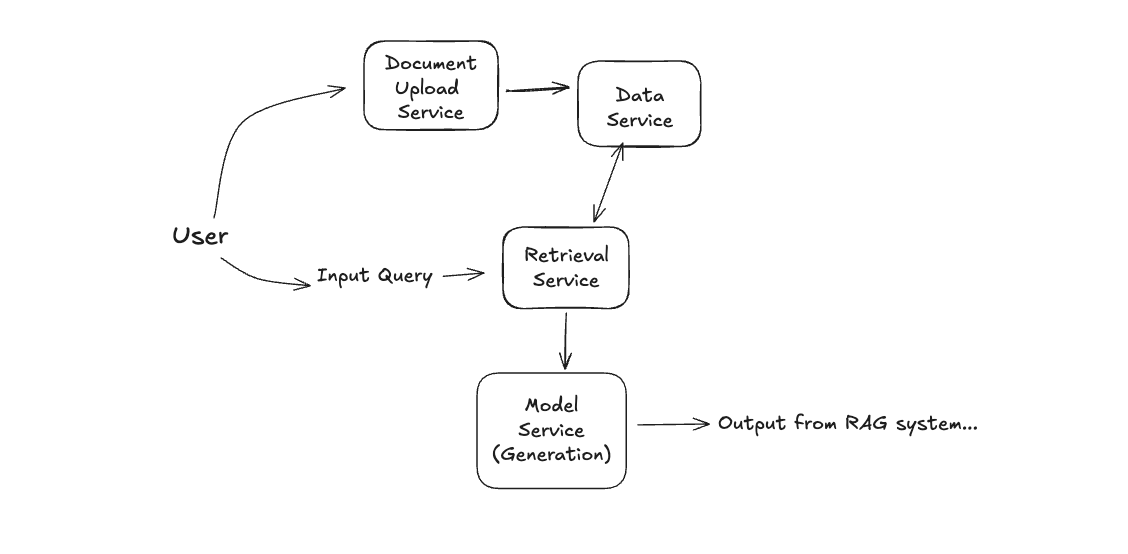
Of course, these services (and the diagram) will be updated significantly, but this is a fine starting point to get the interview going. Your goal in the remainder of the interview is to step through each of these services and outline the RAG system
Data
A fundamental aspect of a RAG system separate from typical LLM designs (e.g. our chatgpt design) is the need for an associated knowledge base. The goal of this knowledge base is to store and index some collection of documents (typically PDFs, but can be anything, images included) that act as context for our model's generated responses. Our focus will primarily be on the most popular use-case: text documents, like PDFs or markdown files.
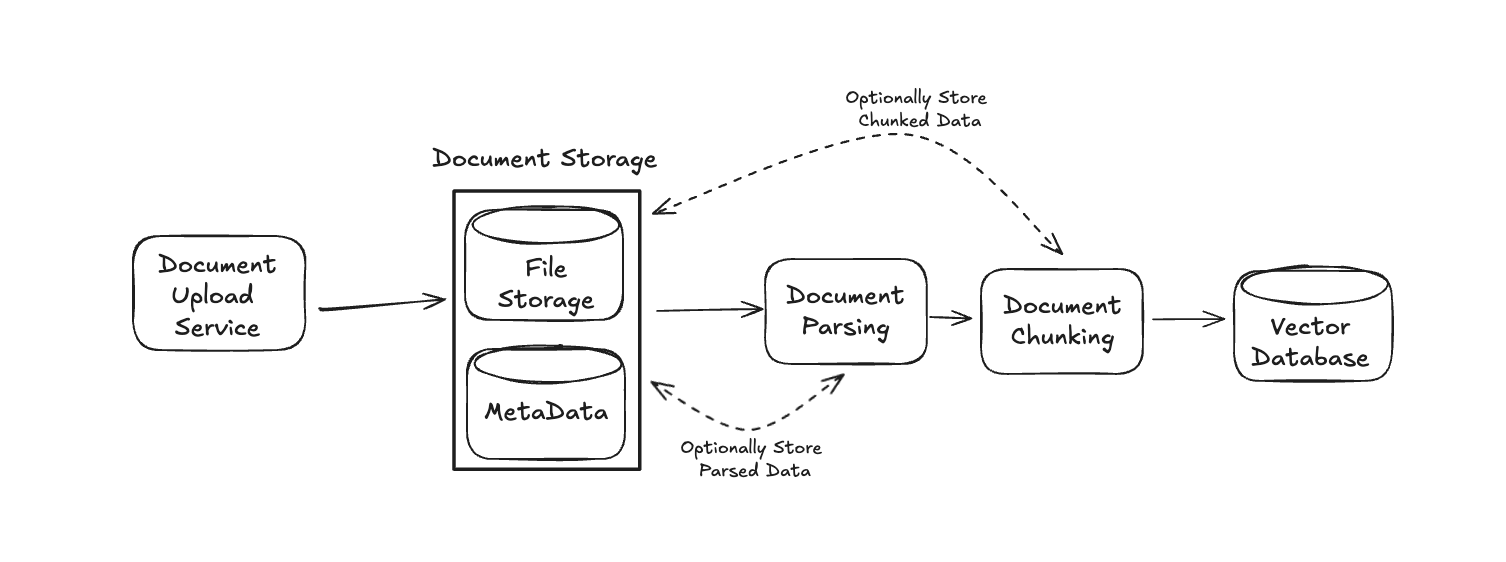
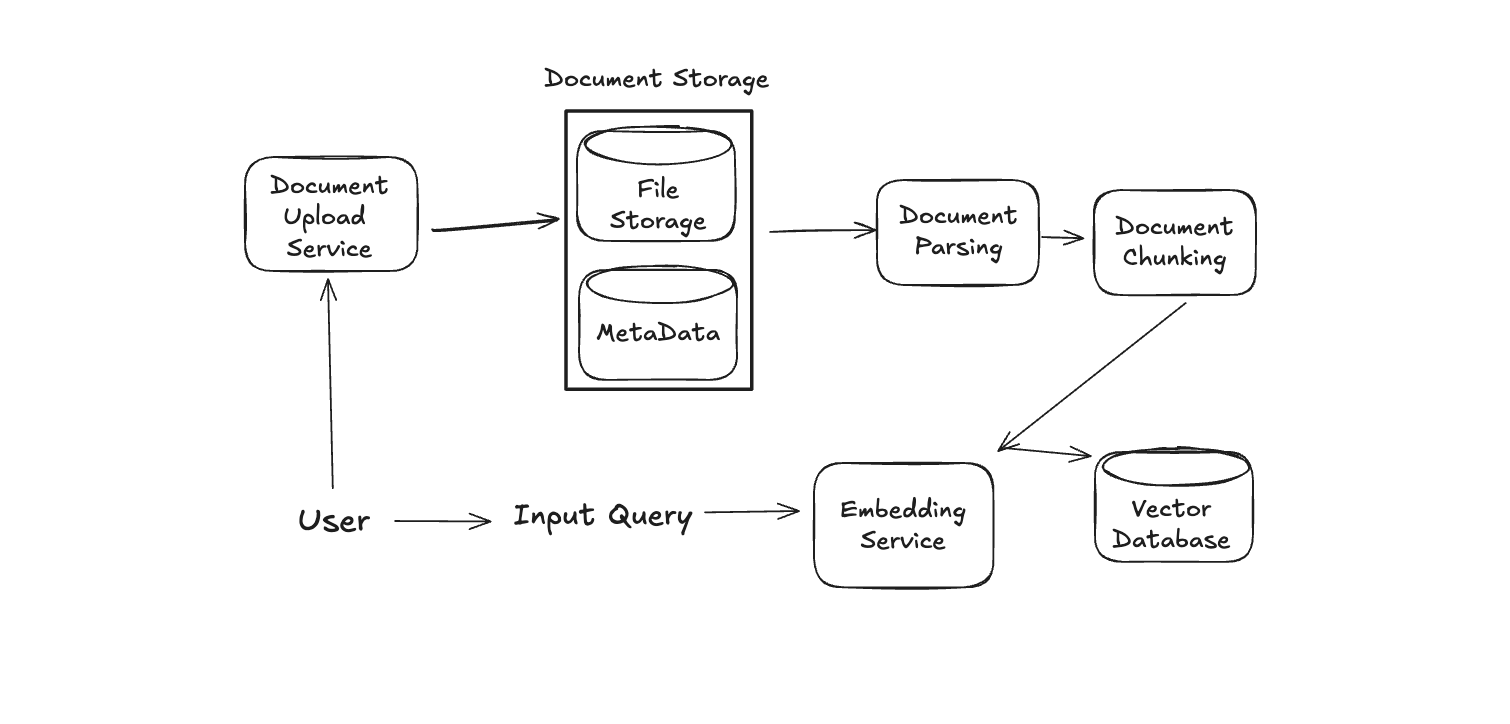
Our Data Service will mirror a typical RAG process, which performs three primary steps in sequence:
- Document Parsing
- Document Chunking
- Chunking Embedding/Indexing
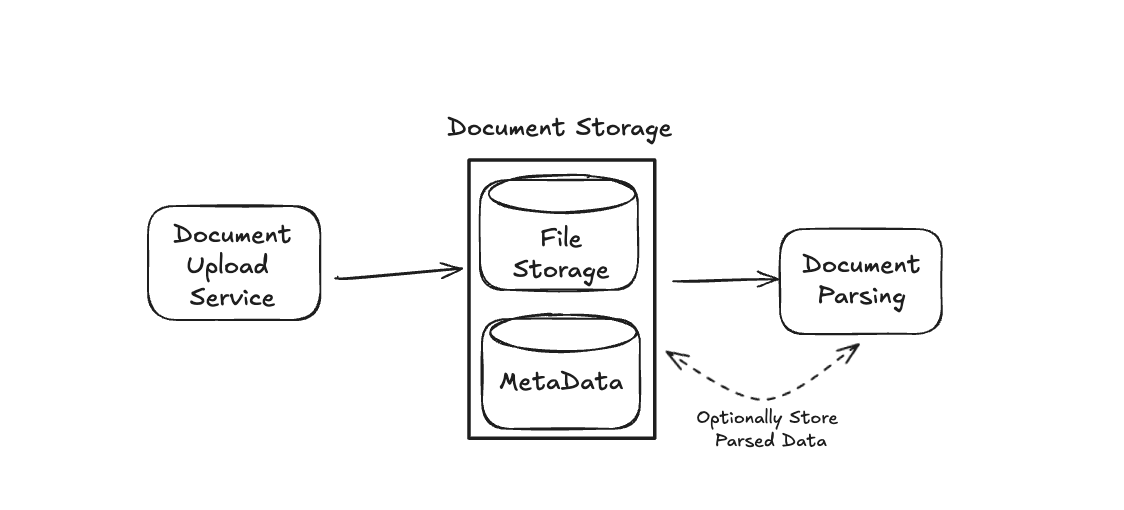
Before diving into the details of each, let's update the Data Service system in our diagram with some additional components, before discussing them below. Namely, we will add components for each step listed above, plus a component for the initial document storage and the eventual vector db storage:
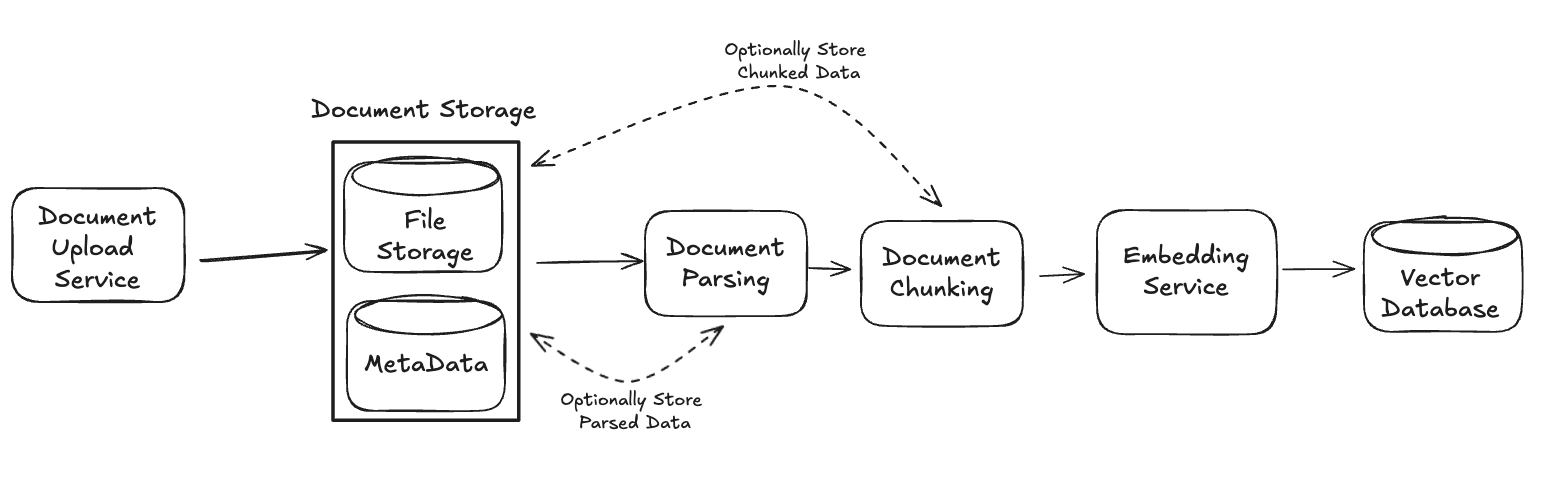
Now, let's walk through each component of our Data Service in turn.
As an obvious first step, we'll need to store any uploaded documents. Assuming these are standard PDF files, we can store the raw documents in some object storage (e.g. S3, GCS, etc.). We may also want to store some basic metadata for these files (filename, size, type, upload time). Our basic metadata document store may have a schema as follows:
documents {
document_id: UUID (primary key)
raw_document_path: STRING (path in object storage)
filename: STRING
file_type: STRING
upload_timestamp: TIMESTAMP
processing_status: ENUM
user_id: UUID
metadata: JSON (file-specific metadata)
}
This is flexible to the specific interview requirements. For some enterprise systems, you may be required to have complete traceability or support advanced features like reprocessing with different chunking strategies without re-parsing documents. For this reason, we optionally store the parsed and chunked documents.
Document Parsing
Document parsing refers to the conversion and extraction of a document's content from an unstructured format (e.g. a PDF or image of a table) into a structured format suitable for language model consumption. With approximately 90% of the world's data living in unstructured documents, this has become a very important area of research.
In early approaches, this was done via rule-based or heuristic-based document parsers that use some combination of patterns, layout rules, and predefined rules to extract content from documents. The more-advanced-but-still-early OCR (Optical Character Recognition) tools (the most popular of which is probably Tesseract) combined rule-based reasoning with early object-detection. As anyone who worked with these tools can tell you, the extraction isn't great - mistakes abound if the document deviates from a very well-separated, typically-structured PDF. For example, if a PDF image has blurring, non-standard characters, or non-text content (e.g. charts or diagrams) things can fail spectacularly.
Advanced approaches for document parsing leverage AI advances in object detection to better extract various types of content (text, charts, tables) across standard and non-standard document formats alike. As I write this (April 2025), this is an active area of research, with new models and advancements coming out all the time. The current top models are listed in the table below, reproduced from the announcement page for the current SOTA model, Mistral OCR:
| Model | Overall | Math | Multilingual | Scanned | Tables |
|---|---|---|---|---|---|
| Google Document AI | 83.42 | 80.29 | 86.42 | 92.77 | 78.16 |
| Azure OCR | 89.52 | 85.72 | 87.52 | 94.65 | 89.52 |
| Gemini-1.5-Flash-002 | 90.23 | 89.11 | 86.76 | 94.87 | 90.48 |
| Gemini-1.5-Pro-002 | 89.92 | 88.48 | 86.33 | 96.15 | 89.71 |
| Gemini-2.0-Flash-001 | 88.69 | 84.18 | 85.80 | 95.11 | 91.46 |
| GPT-4o-2024-11-20 | 89.77 | 87.55 | 86.00 | 94.58 | 91.70 |
| Mistral OCR 2503 | 94.89 | 94.29 | 89.55 | 98.96 | 96.12 |
Novel approaches, such as those listed in the table above, work across a huge array of formats and languages, with abilities to extract content from very complex documents. In Mistral OCR's demo video, they extract content from the AlphaFold paper with great success:
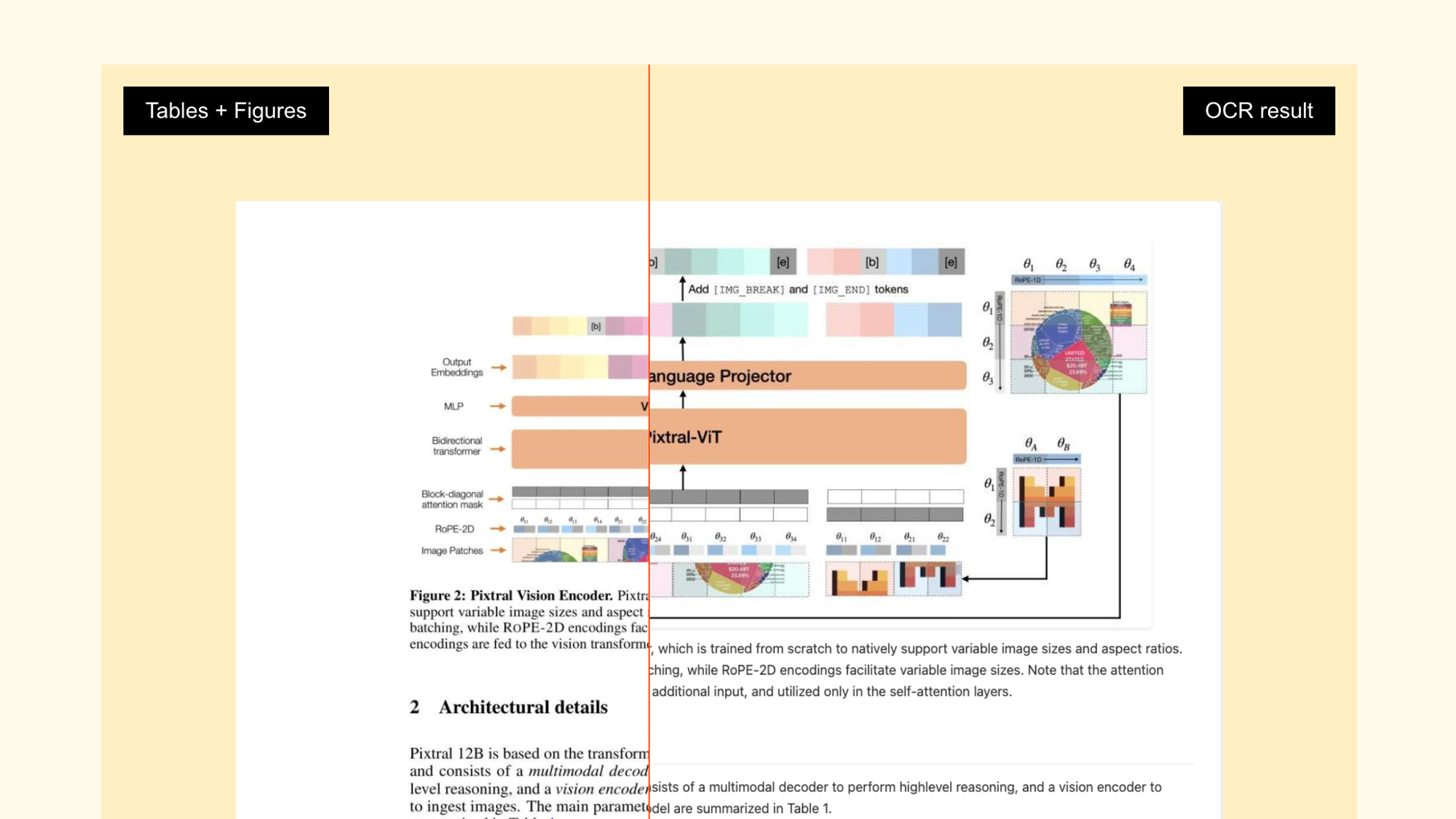
These tools typically work by taking as input some document image and running it through a series of steps before returning some structured output consisting of two separate entities: text data (e.g. the text content itself plus meta information and the location of the text in the document) and non-text data (e.g. the location of any images or diagrams in the document). These in-between steps vary by algorithm, but almost always consist of a layout detection algorithm (to draw bounding boxes around different types of content) followed by extraction. For example, the layout detection may identify a research paper's Abstract, and the following extraction algorithm may use some combination of OCR/CV techniques to identify the content type, store any metadata, parse the content, and extract it.
A successful end to this step is the extraction of content from the user-uploaded data.
Document Chunking
The next step is document chunking. This step is needed as data extracted from the previous step (e.g. long paragraphs) may otherwise be too long. Imagine, for example, we extracted text from a book. In order to use that text as context for our LLM later on, we'll need to embed it into a vector representation. But very long vectors are problematic in this context for a few reasons:
- Too broad: info is too broad for effective citation/recall.
- Context Length: While some newer architectures handle longer context better than others, many common models used with RAG (e.g. attention-based GPT models) struggle with handling long-context inputs effectively, or have otherwise prohibitive token limits.
The goal of document chunking is to work around these limitations by breaking our text data into smaller chunks of data. Each chunk will be vectorized and stored in a database, acting as its own atomic unit of information available for retrieval. In doing so, we can not only reduce memory constraints, but allow for more precise, higher-quality retrieval! Below is an example of chunking text about mlprep (this very site!) using Greg Kamradt's ChunkViz:
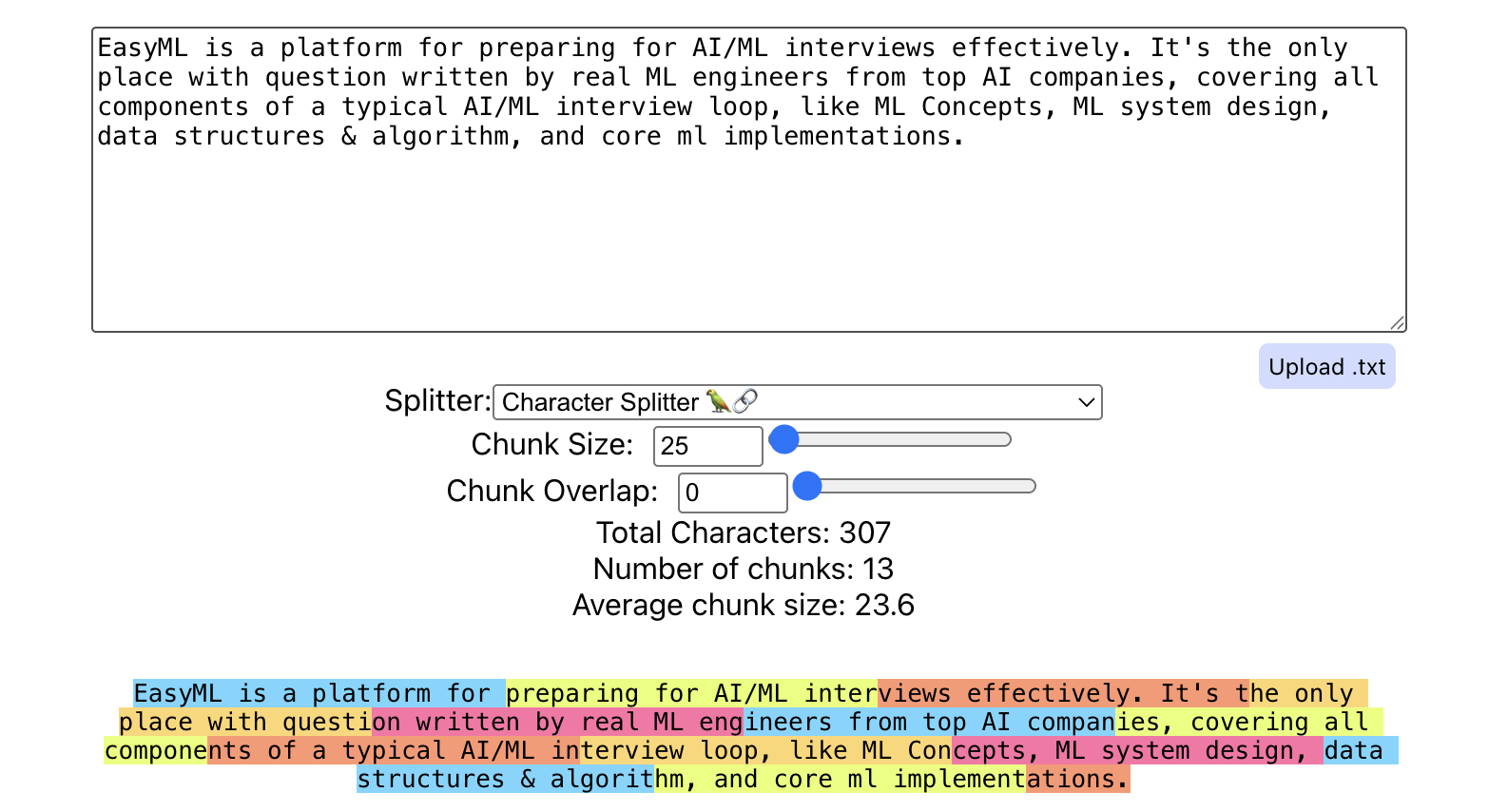
In an interview, you may be asked which chunking strategy you'd use. Several popular options exist (see langchain-text-splitters), including:
- Text Character Chunking: Splits based on characters and measures chunk length by the number of characters. Available as
CharacterTextSplitter. - Recursive Character Chunking: The most popular choice for generic text. Available as
RecursiveCharacterTextSplitter. - Structure-Specific Chunking: Thre is an array of content-specific chunkers. For example,
HTMLHeaderTextSplittersplits HTML headers,Languageallows you to split across different coding languages,RecursiveJsonSplitterworks for nested JSON, etc. - Semantic Chunking: Split text based on semantic similarity. Available via
SemanticChunker. Of course, this is just a sample of the available chunkers. There are many other options, (length-based chunkers, regex chunkers, sentence splitters, etc.), and when in doubt, you can always roll out your own!
But given so many options, how should you choose which chunker to use? There is no one-size-fits-all answer here - in an interview, you can start by mentioning strategies you're familiar with, but don't just jump into an answer. Mention to the interviewer that the choice of chunking should be determined after consulting several factors:
- Question Type: Are users expected to ask true/false questions? Simple facts, or more nuanced questions that reference multiple documents? Is semantic similarity relevant or is syntactic similarity enough?
- Model Context Length: Chunk size affects how much context can be fed as input to a model. The finite context lengths of the LLM will affect how long your chunks can be. Whichever chunking technique you use, you'll have to account for this so you don't create chunks that are too large.
- Document Structure: Is your document mostly text, or is it a complicated hodgepodge of multiple modalities?
- Embedding Model: The architecture and training data of your embedding model directly impact chunking strategy. Models like Sentence-BERT excel with sentence-length chunks, while text-embedding-3-large (OpenAI) handles paragraphs better. If your model was trained on short snippets, large chunks may dilute semantic relevance – experiment to align chunk size with the model’s "native" context window.
Tip
This discussion is also a good place to mention the RAG system-wide affects of chunking choice, such as:
- Retrieval Quality: The entire goal of our RAG system is enhancing contextual information. Effective chunking achieves this goal by increasing our retrieval relevance and quality.
- Model Latency and Cost: LLM inference costs scale with the size of retrieved context chunks. Larger chunks increase token usage (and costs) while also slowing down response times. However, overly small chunks may lack sufficient context, leading to vague or inaccurate answers.
- Vector DB Latency and Cost: Minimizing the number of chunks minimizes the latency of our VectorDB, and the cost of storage grows linearly with the number of chunks.
- Model Hallucinations: Excessive context may lead to LLM hallucinations. There's a delicate balance between retrieval precision and contextual richness.
At this point, our system has parsed a document and turned the extracted content into chunks. Our next step is to store it in a way appropriate for retrieval.
Chunking Indexing
After performing the above step, each chunk will be vectorized and stored in a database, acting as its own atomic unit of information available for retrieval. In order to ensure that relevant chunks to a given user query can be retrieved in an efficient manner, we need to index those chunks appropriately.
But how do we index our chunks of data? There are three main strategies:
- Traditional Retrieval: Traditional retrieval methods match user queries with exact terms, think syntactic similarity. Text from a user's input query will be compared against the indexed collection of documents. The most popular example of Traditional Retrieval is Elasticsearch* While this method is simple and fast, it fails to retrieve information based on semantic similarity (e.g. He likes steak and the man enjoys beef would be treated as two completely documents).
- Vector Retrieval: Store numeric embeddings of the chunked data, and measure the similarity between these embeddings and the embedded user input query.
- Knowledge Graph Retrieval: Create structured (e.g. hierarchical) relationships between entities in to chunked data, and use the user query to traverse this graph to find the most relevant information.
These days, RAG applications almost always use vector-based retrieval methods, and that's likely what your interviewer wants to hear! Of course, your job is to mention why it's a great choice for the task, and there are several reasons. For large datasets, retrieving embeddings is very fast and can scale considerably. Embeddings allow us to capture and compare against the semantic similarity of a query, and can even help us easier account for out-of-vocabulary terms. As a bonus, by indexing the data as embedding vectors, we can make use of popular vector databases (e.g. pgvector, milvus, or one of the many other options if they're still around).
See the image below (from LangChain)for a high-level overview of a VectorDB:
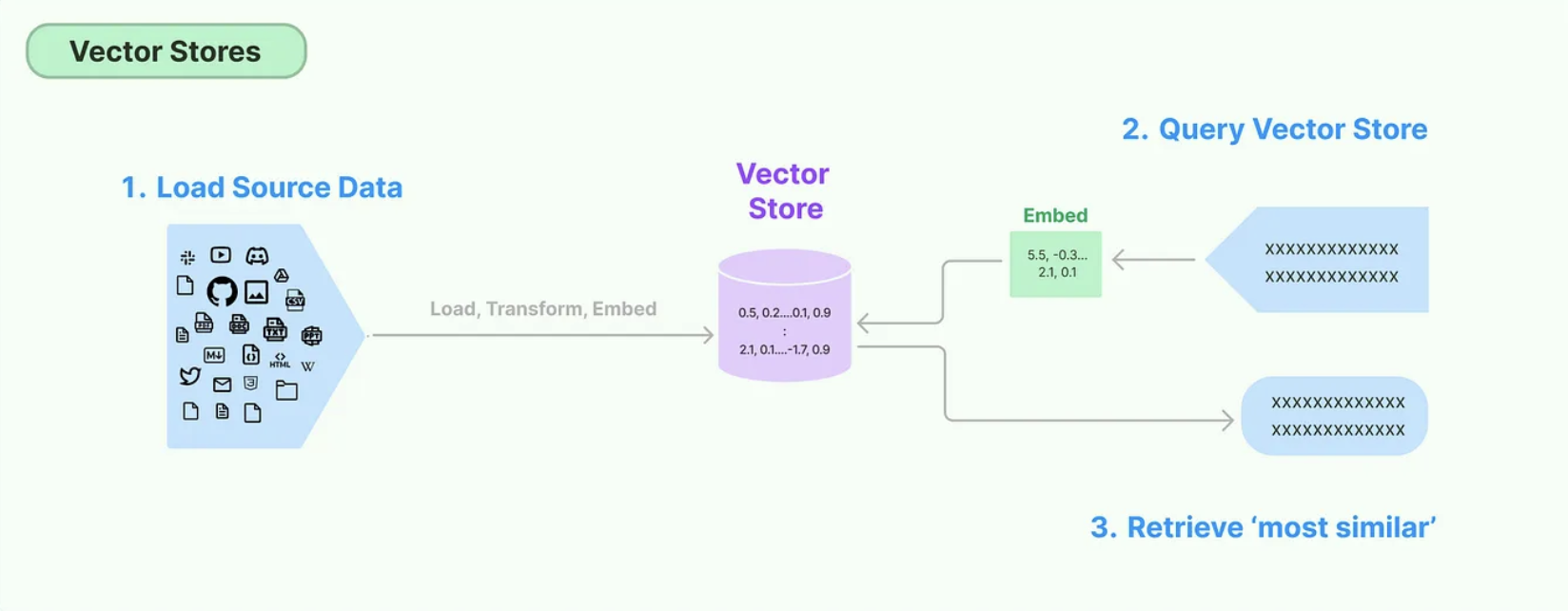
To be clear, VectorDBs aren't always the best choice for RAG systems .
VectorDBs excel at semantic similarity for unstructured data (e.g., finding all documents discussing “financial risk mitigation strategies” even if the exact phrase isn’t used), but are unnecessary if your domain relies on precise terminology (e.g. legal contracts, medical codes) where synonyms are rare, in which case traditional keyword search may suffice.
They also struggle with multi-hop reasoning. For example, answering “What’s the connection between Project X’s budget overrun and the CEO’s latest email?” requires traversing relationships between entities (projects ↔ budgets ↔ people) which knowledge graphs explicitly encode. In addition, if user queries demand temporal reasoning (e.g., “How did our Q3 marketing strategy evolve from Q2?”), vector similarity alone often misses time-based context.
Note
The tradeoffs between VectorDBs and knowledge graphs boil down to three factors:
-
Query Complexity:
- VectorDBs: Best for single-concept searches (“steak nutrition”).
- Knowledge Graphs: Better for relational queries (“how do steak prices affect beef exports?”).
-
Data Structure:
- VectorDBs: Work “out of the box” with unstructured text (PDFs, emails).
- Knowledge Graphs: Require structured entity-relationship modeling (ideal for databases, taxonomies).
-
Maintenance Overhead:
- VectorDBs: Low – just re-embed updated documents.
- Knowledge Graphs: High – adding new data often requires schema changes and manual curation.
For most applications, a sufficient interview answer is to start with a VectorDB before augmenting it with lightweight knowledge graph techniques. That process typically looks like:
- Use LLMs to extract entities/relationships during chunking (e.g., “Document A mentions Project X and CEO Smith”).
- Store these relationships as metadata in your VectorDB.
- During retrieval, first fetch semantic matches via embeddings, then filter/rerank using entity links.
In our case, we don't require as with most RAG applications, we'll just opt to use a VectorDB.
Embeddings
Because we're using a VectorDB, we'll need to determine an appropriate embedding technique for our documents. We mentioned this above, but in an interview setting, you'll be expected to go into detail into embedding selection.
Text Embeddings
Several popular techniques for text embeddings exist. In general, they can be split between sparse and dense representations, with popular examples including:
- Sparse Embeddings: Sparse embeddings rely on traditional tools like TF-IDF and BM25, which represent documents as high-dimensional vectors with many zero values. These methods are fantastic at capturing exact keyword matches and deliver fast, computationally efficient searches—ideal when you're processing large volumes of documents in real time. For example, if your system requires precision in identifying exact terms, such as in legal documents or technical manuals, sparse embeddings provide a reliable baseline. They also work well as an extra layer of validation alongside more semantically rich approaches.
- Dense Embeddings: Dense embeddings take a different approach by using neural networks to transform text into lower-dimensional vectors that encode contextual meaning throughout every dimension. This means they capture deeper semantic relationships, making them great for systems where the user’s query might not match the exact words in your documents. Although these methods come with higher computational demands, they’re particularly effective in conversational settings or when dealing with unstructured texts like emails and customer support chats. For instance, sentence transformers like SBERT and MPNet are optimized for sentence-level tasks and work wonderfully for chatbots and Q&A systems. Similarly, contextual embeddings—found in models like OpenAI’s text-embedding-3 series, Cohere’s offerings, and open-source options like BGE, E5, and BAAI—excel at processing longer, more complex passages.
- Specialized RAG Embeddings: Sometimes you need a tool that’s been crafted specifically for retrieval tasks. Specialized RAG embeddings such as SGPT and FlagEmbedding are fine-tuned with retrieval in mind. Their design focuses on improving retrieval accuracy in scenarios where domain-specific nuances play a major role. If you're building a system that supports technical support, niche research areas, or any application requiring extra precision, these specialized models can offer that extra edge in matching relevant content.
- Hybrid Approaches: Finally, there are hybrid approaches that blend sparse and dense embeddings to leverage the best of both worlds. By combining the rapid, keyword-focused matching of sparse methods with the semantic depth provided by dense models, hybrid systems strike a solid balance. This approach is particularly beneficial in environments where user queries can range widely—from precise, exact-match searches to those requiring more context and nuance. In practice, a hybrid setup is often the route to building a robust system that gracefully adapts to diverse search needs.
For RAG systems, the most popular choice as of today (April 2025) is probably OpenAI's text-embedding-3-large, which offers excellent performance and supports very long contexts (up to 8K tokens). For open-source alternatives, BGE-large-en and e5-large-v2 remain top contenders with nearly comparable quality to commercial options. For multilingual applications, BAAI's multilingual embeddings and OpenAI's embeddings (see this conversation) have shown the strongest performance across different languages.
Image Embeddings
Earlier we discussed that modern OCR solutions can also grab images/diagrams/charts/etc., so if our RAG system needs to handle multimodal content, then these are in the scope of design. Recall that the goal of image embeddings is to transform visual data into vector representations that capture semantic content, enabling image-based retrieval and cross-modal matching.
Popular models include CLIP (Contrastive Language-Image Pre-training), which aligns visual and textual embeddings in a shared space, and DINOv2, which generates high-quality visual representations without requiring text pairing. These models can encode images into vectors that represent visual concepts, allowing users to search document collections using either text queries ("Show me charts about revenue growth") or image queries (uploading a similar chart to find related content). For document-centric RAG systems, image embeddings are particularly valuable for diagrams, charts, and other non-textual information that might be missed by text-only approaches. Specific image embedding techniques include:
- Supervised CNN-based Models: Traditional approaches like ResNet and EfficientNet, pre-trained on ImageNet, provide general-purpose image embeddings. While effective for basic categorization, they often lack the semantic richness needed for document understanding.
- Self-Supervised Vision Transformers: Models like DINOv2, MAE (Masked Autoencoders), and BEIT learn robust representations without requiring labeled data. These models excel at capturing structural and semantic information in diagrams, charts, and document layouts without needing paired text.
- Vision-Language Models: Cross-modal embedders like CLIP, SigLIP, and BLIP align visual and textual spaces, enabling powerful zero-shot capabilities. These models are particularly valuable for RAG systems as they allow for semantic matching between text queries and visual content (or vice versa).
- Document-Specific Visual Encoders: Specialized models like Donut, LayoutLM, and DocFormer jointly encode both textual content and visual layout information (great if our RAG is for complex document structures like forms, tables, and scientific papers with equations!).
In the context of RAG systems, CLIP-based models (or their open-source alternatives like OpenCLIP) have become the de facto standard due to their ability to bridge text and image modalities. For document-heavy applications, combining these with layout-aware models can significantly improve retrieval quality. As of April 2025, the most effective approach for document RAG combines specialized document visual encoders for structural understanding with vision-language models for semantic comprehension.
In any case, when discussing embedding selection for RAG a system design interview, mention the tradeoffs involved:
- Dimensionality vs. Quality: Higher-dimensional embeddings generally capture more information but require more storage and compute. The text-embedding-3-large model (3072 dimensions) provides excellent quality but doubles storage requirements compared to earlier 1536-dimension models.
- Context Length vs. Performance: Longer context windows in embedding models improve representation quality but increase computational costs. Models like text-embedding-3-large (8K context) excel with longer chunks but process fewer documents per second than models with shorter context windows.
- Batching Efficiency: Some embedding models (particularly open-source ones) can efficiently batch multiple documents, significantly reducing embedding time when processing large collections. Consider models that parallelize well if indexing speed is critical.
- Quantization Opportunities: For large-scale deployments, embedding vectors can be quantized from 32-bit floats to 8-bit integers, reducing storage requirements by 75% with minimal quality loss. Most vector databases now support this optimization automatically.
- Domain Specialization: General-purpose embeddings may underperform on highly technical content. Domain-specific fine-tuning (e.g., for legal, medical, or scientific documents) can improve retrieval quality by 15-30% but requires additional training infrastructure.
That is, you want to communicate to your interviewer that not only is your solution correct, but that it balances quality, cost, and performance requirements.
Our system design will centralize these capabilities into a unified Embedding Service responsible for generating both text and, if necessary, image embeddings.
todo: make above image actually just show embeddings
This shared service will handle embedding generation for both the indexing pipeline and real-time user queries, ensuring consistent vector representations across the system. By consolidating embedding logic into a single service, we can more efficiently manage model deployment, versioning, and potential hardware acceleration (e.g., GPU resources). The Embedding Service will expose a standardized API that accepts either text or image inputs, automatically selecting the appropriate model, and returning normalized vectors ready for vector database storage or similarity search.
Modeling
On the modeling side, we have two things to handle for our RAG system design:
- Modeling relevant to the Retrieval service.
- Modeling relevant to the Generation service.
Here we will finally begin to trace the journey of the user's input query!
query -> preproc -> query expansion -> retrieval -> prompt engineering -> llm gen -> post-preproc
Retrieval
The Retrieval Service is in charge of taking a user's query, embedding it it into the same space as the indexed data, and then comparing that query embedding with our stored embeddings to retrieve the most relevant chunks of data.
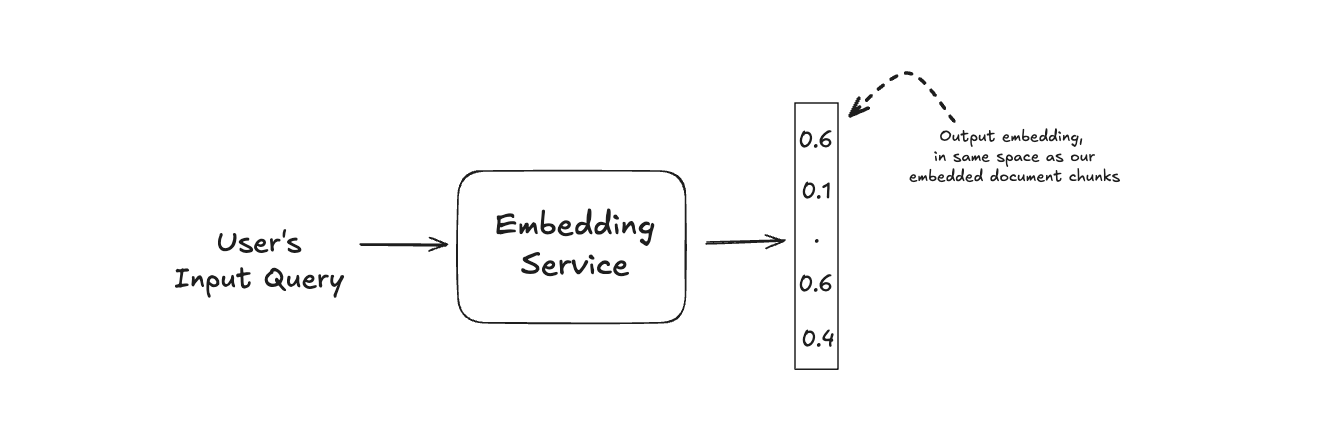
We already have an Embedding Service to handle the encoding of user-input into an embedding vector, which the input-query will feed into.
After the embedding, our focus is on retrieving the most relevant chunks of data to a user's input query. However, in production RAG systems, we typically add two main steps before the conversion, Input Preprocessing/Sanitization and Query Expansion.
Input Preprocessing/Sanitization
Before embedding a user's query, we need to preprocessing to ensure optimal retrieval quality. Input preprocessing involves normalizing text (lowercasing, removing excess whitespace), handling special characters, and filtering noise that could degrade embedding quality. For domain-specific RAG systems, this might include expanding acronyms (e.g., "ML" to "machine learning"), standardizing terminology, or applying custom tokenization rules. This step is particularly crucial for enterprise applications where queries might contain company-specific jargon, product codes, or other specialized vocabulary that embedding models weren't explicitly trained on. Effective preprocessing can improve retrieval precision by 10-15% in technical domains by aligning user query formats with indexed document conventions.
Query Expansion
Query expansion enhances retrieval by enriching the original query with additional relevant terms or context. In RAG systems, this technique addresses the "vocabulary mismatch problem" where users may use different terminology than what appears in the indexed documents. Traditional approaches use synonyms, hypernyms, or related terms from knowledge bases like WordNet to expand queries. However, modern RAG systems increasingly leverage LLMs for context-aware query expansion, generating multiple variants of the same semantic query to increase retrieval coverage. For example, the query "heart attack prevention" might be expanded to include "myocardial infarction risk reduction" and "cardiovascular disease prevention strategies" to match medical literature using formal terminology.
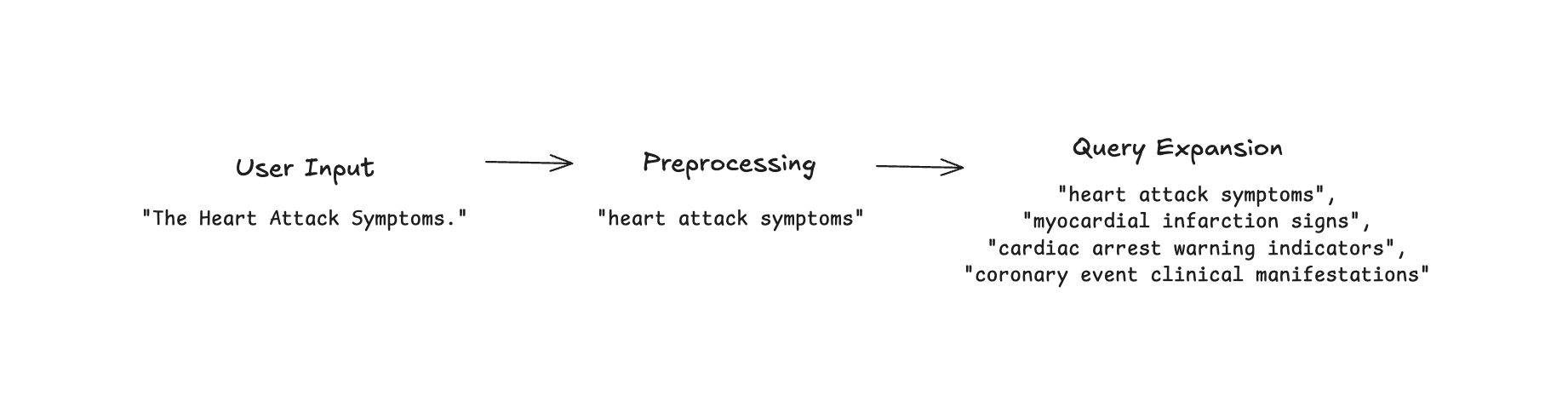
The primary benefit of these steps is improved recall, especially for short or ambiguous queries. By searching with multiple query formulations simultaneously, RAG systems can retrieve relevant documents that might otherwise be missed due to terminology differences or domain-specific language. This technique is particularly valuable in specialized fields like healthcare, legal, or scientific research, where precise technical language might create barriers between user queries and relevant content. In practice, query expansion typically involves generating 2-5 alternative formulations of the original query, embedding each separately, and then performing nearest neighbor search with all variants, often with a weighted aggregation of results. While this approach increases computational overhead, the retrieval quality improvements (typically 15-25% higher recall) justify the additional processing in most production RAG deployments.
Let's add these to our system design:
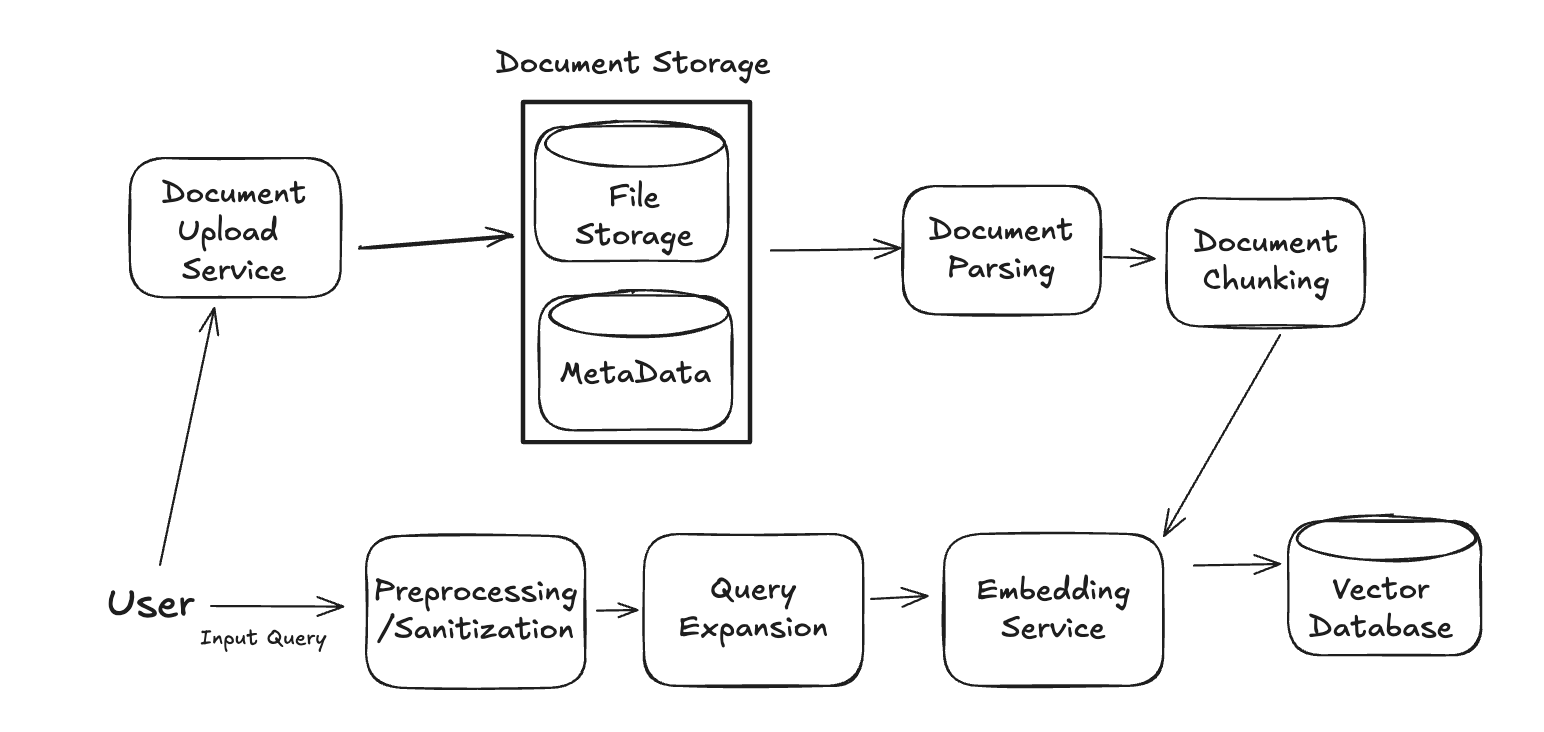
Great, now a user's input has been cleaned up. For a given query embedding, the system now needs to find the nearest neighboring data chunk embeddings that are most similar. This is a classic neareast neighbor search problem, and luckily for us, several tried-and-true techniques exist! There are two main things to take into account here: the nearest neighbors algorithm and the similarity measure.
The Nearest Neighbors Algorithm
At its core, the nearest neighbors problem involves finding the k closest points to a query point. For RAG systems, this translates to finding the most semantically similar document chunks to a user's query. As embedding dimensions typically range from 768 to 3072, this becomes computationally challenging with large document collections. In terms of nearest neighbor approaches, there are two main classes of approaches: exact nearest neighbors and approximate nearest neighbors.
Exact Nearest Neighbors (Exact NN):
The simplest approach computes the distance between the query vector and every document vector in the database, sorting results to find the closest matches. While guaranteed to find the true nearest neighbors, this is a brute-force approach and scales poorly, with complexity where is the number of vectors and is their dimensionality. For small collections (under 100K documents), this might be feasible, but in production RAG systems with millions of chunks, exact search becomes prohibitively expensive, especially for real-time applications with sub-second latency requirements. The most popular exact nearest neighbor algorithm is K-Nearest Neighbors (KNN). If the interview requirements mention a large amount of data to index, you do not want to use KNN as your choice of nearest neighbors algorithm. You can mention it as a brute-force approach, but make sure to explain the pitfalls of exact nearest neighbors before selecting an approximate nearest neighbors approach instead.
Approximate Nearest Neighbors (ANN):
These techniques trade perfect accuracy for dramatic speed improvements, typically finding 95-99% of the true nearest neighbors while reducing search time by orders of magnitude. For RAG applications, this accuracy-speed tradeoff is almost always worthwhile, as slight variations in retrieval results rarely impact the final generated response quality. The most popular ANN approaches fall into several categories:
- Graph-based NN: Algorithms like HNSW (Hierarchical Navigable Small World) construct a graph where each vector connects to its neighbors, creating a navigable structure that allows for efficient traversal to the query's vicinity. HNSW is widely used for RAG systems because it handles high-dimensional embeddings well and offers excellent query performance. From a system design perspective, its main drawback is memory usage (typically 50-100 bytes overhead per vector) and build time complexity, as graph construction is more computationally intensive than other methods. However, its query speed and recall quality make it the current industry standard for production RAG systems.
- Clustering-based NN: Methods like IVF (Inverted File Index) partition the vector space into clusters, allowing the search to examine only relevant clusters instead of the entire dataset. During indexing, vectors are assigned to their nearest centroids, and at query time, only clusters close to the query vector are searched. This approach offers moderate memory usage and good query performance, especially for very large datasets where examining even a portion of vectors would be too expensive. The system design tradeoff is sensitivity to the number of clusters – too few diminishes the speed advantage, while too many reduces recall quality. IVF works well in RAG systems with clearly separable document topics but may underperform when content domains overlap significantly.
- Tree-based NN: Algorithms such as k-d trees and Ball trees recursively partition the vector space, creating a searchable tree structure. While efficient for low-dimensional data (under 20 dimensions), they suffer from the "curse of dimensionality" and often degrade to near-linear search time with high-dimensional embeddings typical in RAG systems. From a system design perspective, they offer low memory overhead and are simple to implement, but their query performance for high-dimensional embeddings makes them unsuitable for most production RAG deployments except those with extremely tight memory constraints or very small, specialized document collections.
- Locality-Sensitive Hashing (LSH): This technique hashes similar vectors to the same bucket with high probability, effectively reducing the search space. LSH uses multiple hash tables to improve recall, with each table using a different hash function. For RAG systems, LSH offers extremely fast indexing times and moderate query performance. However, it typically requires more storage than graph-based methods due to the multiple hash tables, and achieving high recall often necessitates significant memory overhead. LSH can be valuable in RAG applications where index build time is a critical constraint or where embeddings change frequently, requiring regular reindexing.
- Quantization-based NN: Methods like Product Quantization (PQ) and Google's ScaNN compress vectors by encoding them with a smaller set of representative centroids, dramatically reducing memory requirements. These approaches are particularly valuable for large-scale RAG systems, as they can reduce vector storage by 4-16x with minimal impact on retrieval quality. The main system design benefit is reduced infrastructure costs and improved cache efficiency, allowing larger document collections to fit in memory. The tradeoff comes in slightly reduced recall quality and higher preprocessing complexity. For enterprise RAG deployments with millions of documents, quantization is often applied alongside other ANN techniques like HNSW or IVF.
In most modern RAG systems, HNSW is the preferred nearest neighbors algorithm due to its excellent balance of query speed, recall quality, and implementation maturity. Popular vector databases like Pinecone implement HNSW as their primary index type, often with additional optimizations like vector quantization to reduce memory usage. Thus, in an interview, a good strategy is to start with HNSW and applying quantization techniques if memory constraints become significant. For extremely large document collections (billions of chunks), consider hybrid approaches that combine IVF for initial filtering with HNSW for refined search, like ivf-hnsw.
Similarity Measures
When retrieving nearest neighbors, the choice of similarity measure determines how "closeness" between vectors is calculated. While the nearest neighbors algorithm often dictates the default similarity measure, your interviewer may ask about the different similarity measures, so you should at least be familiar with the most popular measures:
- Cosine Similarity is the most widely used measure for text embeddings, focusing on the angle between vectors rather than their magnitude. This normalization makes it robust to document length variations and is particularly well-suited for semantic text retrieval. Most embedding models, including OpenAI's text-embedding series and sentence transformers, are specifically optimized for cosine similarity.
- Euclidean Distance (L2 norm) measures the straight-line distance between vectors and works well for embeddings where magnitude carries meaningful information. Some visual embedding models and specialized scientific embeddings perform better with Euclidean distance, though it's less common for general text RAG systems.
- Dot Product offers computational efficiency and is mathematically equivalent to cosine similarity when vectors are normalized to unit length (which most modern embedding models do internally). Many vector databases use dot product by default for performance reasons.
See an overview of the most popular similarity measures in the below image by Maarten Grootendorst:
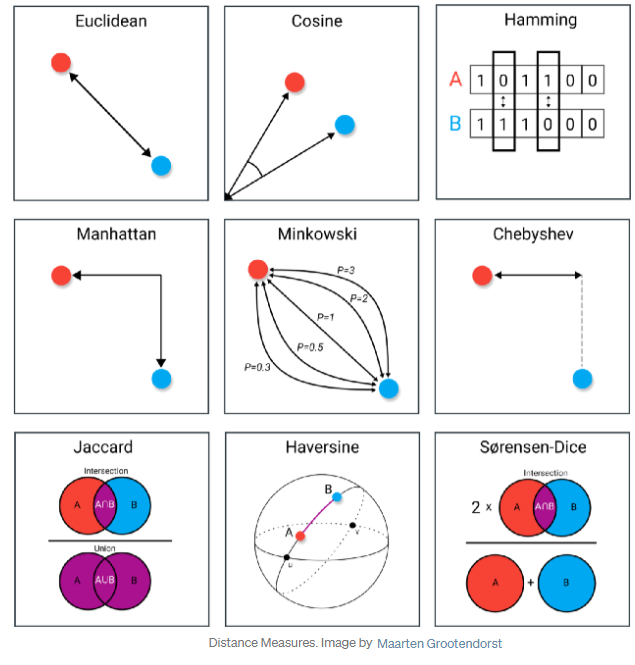
In practice, the decision process is straightforward: if using text embeddings from models like OpenAI, Cohere, or most open-source text embedders, cosine similarity (or dot product with normalized vectors) is almost always the optimal choice. Custom similarity measures become relevant primarily when working with domain-specific embeddings (e.g., molecular structures, geospatial data) or when combining multiple embedding types in the same index. For standard document-based RAG systems, the default similarity measure of your chosen vector database will typically yield excellent results without additional configuration.
On the design side, these are baked into our Retrieval Service, so our overall diagram will largely stay the same.
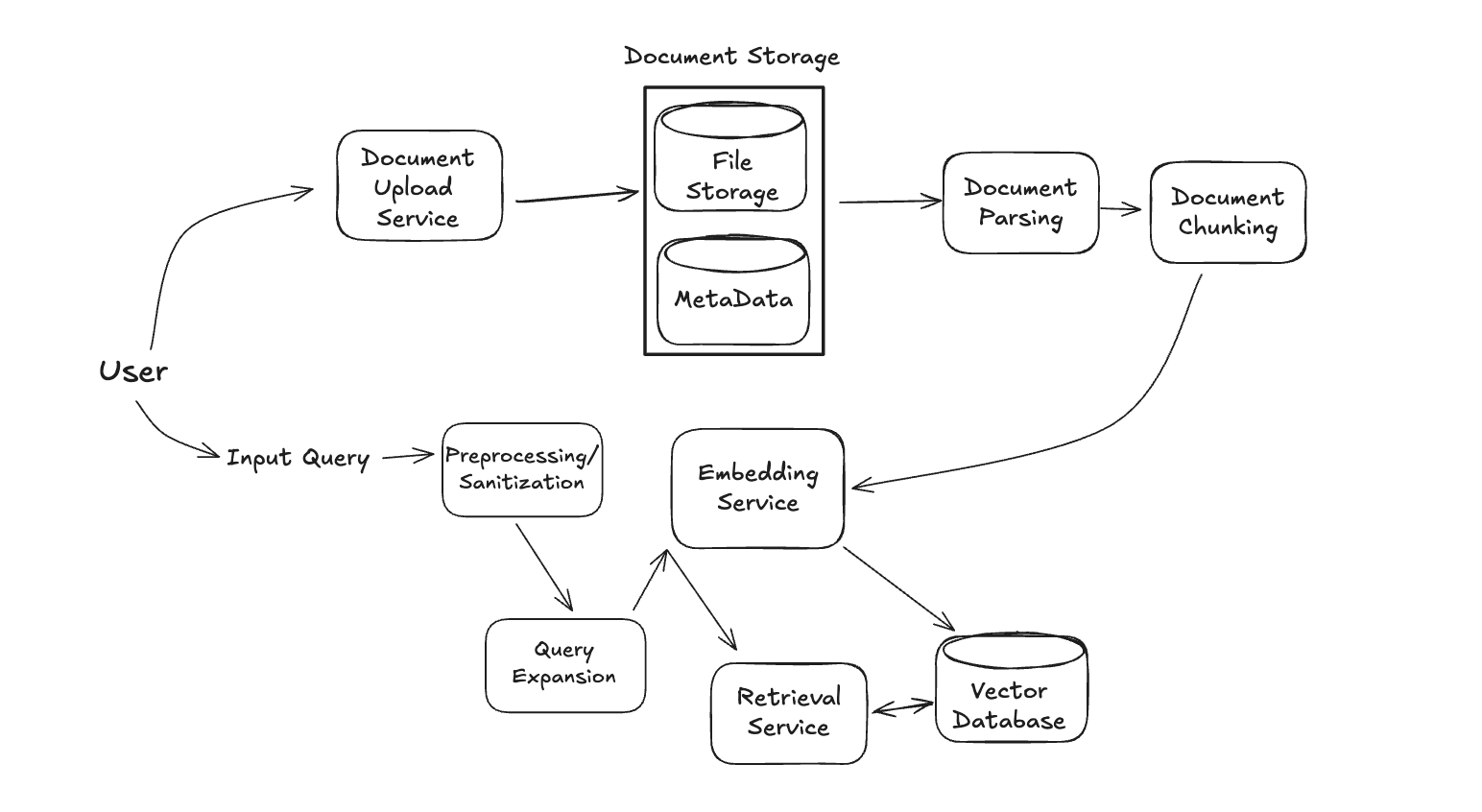
So, at this point, our system takes in a user's input query, turns it into an embedding, and compares that to the embeddings of our document chunks. However, before we move onto the final Generation Service, let's discuss one issue with current RAG systems: the recall quality of the retreival.
Reranking
We're optimizing for fast semantic search across embedding vectors, where the embedding vectors themselves are numerical compressions of our text information. This embedding is required for us to achieve fast vector search, but comes with the cost of information loss. As a result, our model's recall@K, _the share of relevant items captured within the top K positions, often falls short of ideal despite advanced embedding models and similarity metrics.
That is, this information loss means that vector search alone might not always surface the most relevant documents, especially for complex or nuanced queries. While we could increase our top_k parameter to improve retrieval recall, we can't simply stuff all these documents into our LLM's context window without degrading its performance – research shows that LLM recall degrades as we add more tokens. This creates a tension between maximizing retrieval recall and optimizing LLM recall.
Rerankers (or cross-encoders) function as a secondary filtration mechanism. Unlike the bi-encoder models used in vector search that separately encode queries and documents, rerankers process query-document pairs through a unified transformer network.While bi-encoders process queries and documents separately, cross-encoders examine them together through a unified transformer network, capturing nuanced relevance that vector similarity might miss.
The process is straightforward: first, we retrieve a broader set of candidate documents (typically 30-50) using fast vector search. Then the reranker evaluates each query-document pair, assigning relevance scores that allow us to select only the most pertinent documents (typically 5-10) for the LLM. Popular models like Cohere Rerank and monoT5 excel at this task.
This two-stage approach balances efficiency with quality - we use computationally expensive reranking only on a manageable subset of documents, while ensuring the LLM receives only the most relevant context. Studies show this typically adds 50-200ms of latency but improves response quality by 20-40%, making it worthwhile for most production RAG systems.
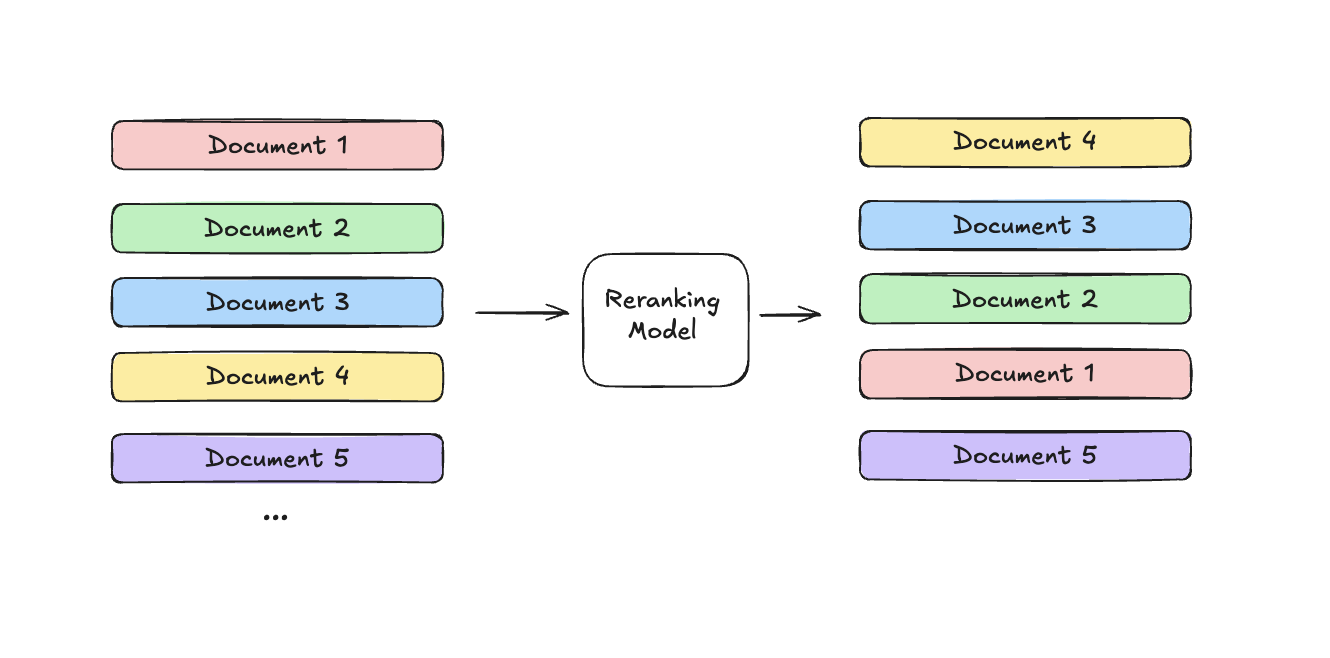
In our RAG architecture, the reranker sits between the Retrieval Service and the Generation Service, acting as a refinement layer. Our process now follows a three-stage pattern: (1) the vector database retrieves a relatively large set of potentially relevant documents (e.g., top 50) using fast approximate nearest neighbor search, (2) the reranker evaluates these candidates to identify the truly most relevant ones (e.g., top 5-10), and (3) only these highest-quality documents are passed to the LLM for generation. This approach balances both computational efficiency and response quality – we keep the vector search fast by limiting expensive reranking to a small subset of candidates, while still providing the LLM with only the most relevant context. For production RAG systems, this 50-200ms latency addition typically yields a 20-40% improvement in answer relevance and completeness, making it well worth the tradeoff.
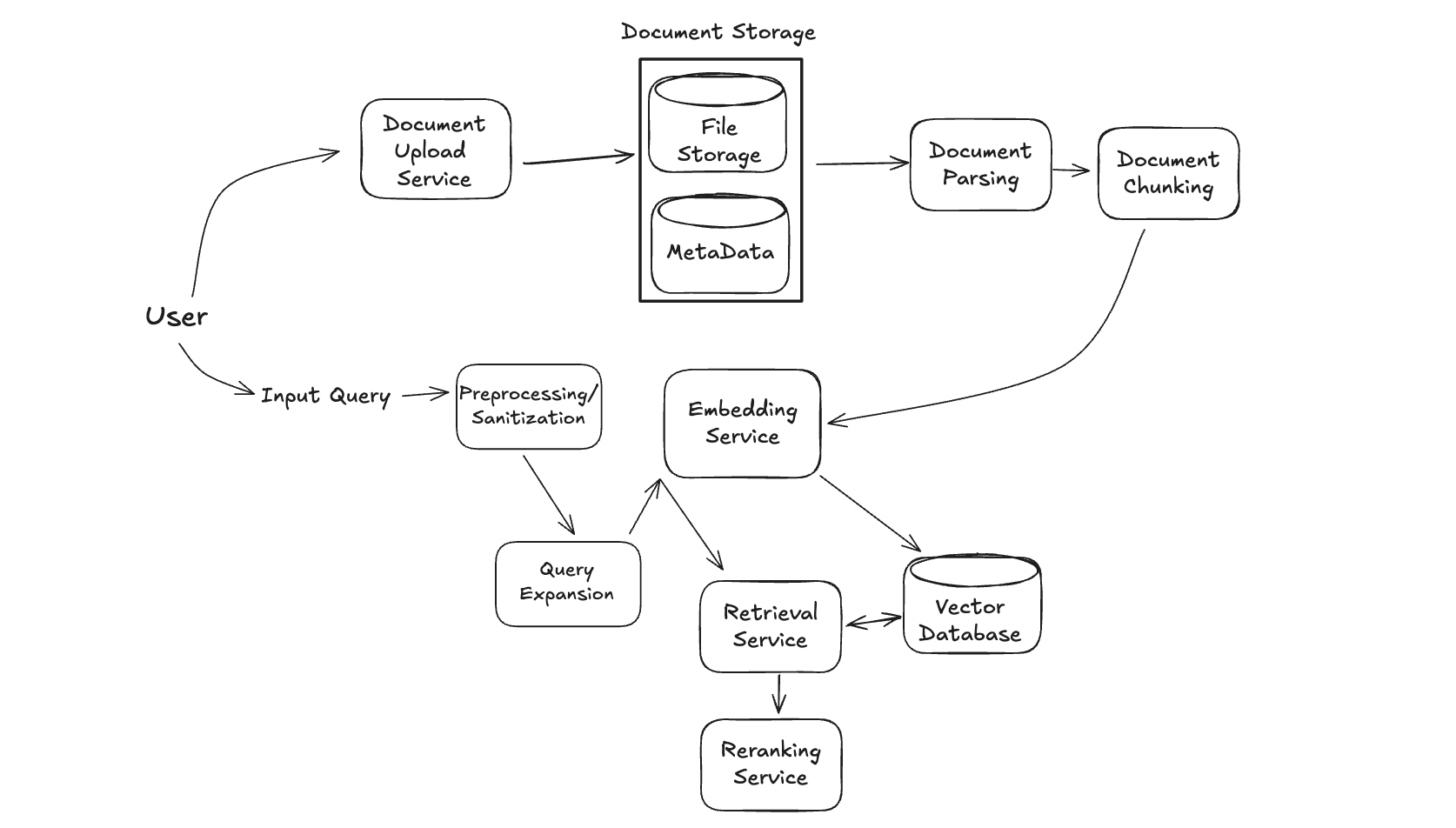
Generation
Finally, we've hit the generation service. This service is responsible for, you guessed it, generating a response based on the user's input, with the contextual help of the retrieved nearest neighbor data chunks. (The name Retrieval Augmented Generation makes a lot of sense now.)
So what does this look like in practice? Actually, in practice this is the most straightforward aspect of the RAG system design interview. It involves several key components:
- The choice of model (LLM)
- Prompt engineering and contextualization
- Sampling techniques
- Post-processing and content moderation
Let's explore each of these components in detail.
Model Choice
For the generative component of a RAG system, you have two primary options: fine-tuning an existing model or using an off-the-shelf pretrained model. Almost every production RAG system uses pretrained models with customized prompting, for a few key reasons:
- Resource Requirements: Fine-tuning requires substantial computational resources and specialized ML engineering talent. Collecting, curating, and managing the training data alone requires significant overhead, and the complexity of model versioning and deployment increases substantially.
- Performance Considerations: While fine-tuned models can achieve higher accuracy for domain-specific tasks, pretrained models with well-crafted prompts often reach 90-95% of this performance, and the performance gap continues to close as base models improve.
- System Flexibility: Pretrained models allow for rapid iteration on prompting strategies and can be deployed instantly without model retraining. It's also super easy to create document/user/etc.-specific prompts.
- Operational Complexity: Fine-tuned models require ongoing maintenance, monitoring, and retraining. (Pretrained models leverage vendor improvements automatically!)
If fine-tuning is appropriate, or your interviewer asks about it, there are techniques for fine-tuning in the context of RAG. Namely RAFT (Retrieval-Augmented Fine-Tuning), which enhances traditional fine-tuning by incorporating retrieved passages during the training process itself, essentially "teaching" the model how to effectively utilize external knowledge. If you're tasked with fine-tuning a domain-specific RAG model (e.g. medicine or law), this is a great approach to follow. That said, we won't discuss fine-tuning more, given the tradeoffs listed above.
Instead, we'll follow the lead of popular commercial RAG systems, like Perplexity or You.com, and use an off-the-shelf pretrained model approach with customized prompting, which offers the optimal balance of performance, flexibility, and operational simplicity for most RAG implementations.
Prompt Engineering
Now recall, before our model is fed any input, after the retrieval and reranking,it content must be constructed via a prompt.
There are several strategies for effective prompting. We discuss some here, and both OpenAI and Anthropic provide guides on effective prompt engineering. This guide is already quite lengthy, so I'll spare going in detail, but at a high-level, RAG-optimized prompt engineering typically follows a structure with these components:
- System instructions defining the assistant's role and response format
- Clear guidelines for using retrieved information
- Explicit instructions to cite sources rather than hallucinating
- The user's original query
- Retrieved context passages, often with metadata (source, date)
- Optional examples of desired output format
The prompt's exact structure significantly impacts retrieval utilization. For instance, placing retrieved passages before the query improves factuality but can lead to more verbose responses, while placing them after the query improves conciseness but may reduce citation accuracy. In enterprise settings, prompts often include additional instructions for handling uncertainty, such as specifying when to acknowledge limitations or redirect users to authoritative sources when information is insufficient.
Let's add a box for Prompt Engineering to our diagram:
Sampling Techniques
The sampling technique determines how the LLM generates text from its probability distribution. While this might seem like a minor detail, it significantly impacts response quality, particularly in knowledge-intensive RAG applications. (All of the popular pretrained LLMs surface these parameters.)
Temperature and Top-p Sampling: Temperature controls randomness, with lower values (0.0-0.3) producing more deterministic responses ideal for factual retrieval, while higher values encourage creativity but risk hallucinations. Top-p (nucleus) sampling restricts token selection to the most probable tokens whose cumulative probability exceeds p, helping balance coherence and diversity.
For RAG systems, the optimal configuration typically involves:
- Temperature: 0.0-0.2 for knowledge-intensive applications requiring high factual accuracy
- Top-p: 0.9-1.0 to allow for some linguistic flexibility while maintaining coherence
- Top-k: Often disabled (set to maximum) when using top-p, as it adds little benefit in factual generation tasks
Some RAG implementations use dynamic sampling parameters based on query classification. For instance, factual queries ("Who invented penicillin?") might use temperature=0, while exploratory queries ("What are some interesting facts about penicillin?") could use temperature=0.3-0.5.
To maintain the highest factuality in our RAG system, we recommend defaulting to a deterministic decoding (i.e. temperature=0) combined with proper prompt engineering, alongside the option to increase temperature slightly for queries requiring more diverse or creative responses.
Post-Processing and Content Moderation
The final critical component before delivering responses to users is post-processing, which ensures quality, safety, and reliability for our production system. This isn't strictly necessary, but mentioning it shows good concern around building for users. The goal of this service is to capture responses before deliverying them to users, and sanitizing them. It may include the following checks:
insert diagram showing post processing step
Factual Consistency Checking verifies that generated content remains faithful to the retrieved documents. Techniques include:
- Entity comparison between source documents and generation
- Natural language inference models to detect contradictions
- Citation verification to ensure references are accurate
Hallucination Detection identifies when the model generates facts not supported by retrieved context. Modern approaches use a separate LLM to evaluate source attribution or implement specialized models trained specifically to detect unsupported claims.
Content Policy Enforcement ensures responses comply with safety guidelines, avoiding harmful, misleading, or inappropriate content. This layer becomes particularly important for domain-specific RAG systems in regulated industries like healthcare or finance.
Response Enhancement can improve the final output with formatting, summarization, or structuring operations. For example, automatically converting lists into bullet points or highlighting key insights.
Adding this post-processing layer increases system complexity but significantly improves reliability. In production environments, robust post-processing has been shown to reduce hallucination rates by 70-80% and harmful content by over 90%, making it an essential component of any serious RAG implementation.
Implementing these components with appropriate caching and optimization strategies ensures our RAG system generates responses that are not only relevant and accurate but also safe and aligned with organizational requirements.
Great, we've designed a RAG system! All that's left is to evaluate it.
Evaluation
Evaluating a RAG system can be tricky since we’re essentially combining two different types of models—retrieval and generation—and both need to perform well for the whole system to succeed. We'll go through both in turn, and then discuss end-to-end methods of evaluation.
Retrieval Metrics
We start by looking at the retrieval part, since it directly affects the quality of generated answers. If you pull up the wrong documents, even the smartest LLM in the world won't fix that, and it'll result in a poor (and likely incorrect) experience for users.
-
Recall@K: Recall@K tells you what percentage of relevant documents your system retrieved within the top K results. For example, if a user asks about "employee benefits," Recall@5 measures whether the documents you need appear within the first five results.
The issue with Recall@K is it doesn't tell you if the best document was first or fifth, just that it appeared at all. This metric is particularly useful for large knowledge bases where comprehensive coverage matters. Good RAG systems typically aim for Recall@5 above 80%, though this varies by domain complexity.
-
Mean Reciprocal Rank (MRR): Mean Reciprocal Rank tries to improve on Recall@K by giving more credit for higher-ranked correct results. If your top result is spot-on, you get full points, and if your first correct document is further down, the points decrease quickly.
The downside with MRR is that it focuses only on the first relevant document and ignores other useful results lower down the list. MRR scores range from 0 to 1, with enterprise systems typically aiming for 0.6+ (acceptable) or 0.8+ (excellent).
-
Precision@K: Measures what fraction of your top K retrieved documents are actually relevant, emphasizing quality over coverage.
High precision means less noise for users and the generation model. Production systems should target Precision@5 above 60%, with excellent systems achieving 80%+.
Generation Metrics
After retrieval, the generation part kicks in, producing your final response. Evaluating this piece is more subjective, but there are still ways to measure it effectively:
-
Accuracy and Faithfulness: Essentially, you check if the generated answer accurately reflects the retrieved documents. Automated metrics like ROUGE or BLEU scores exist, but honestly, they're pretty weak at capturing nuance. The best evaluation here is usually still human judgment, checking if the model is actually faithful to the source.
Modern approaches use specialized NLI models to compare generated text against source documents, or implement citation mechanisms to make verification easier. You can also check consistency by asking the same question multiple times—high variance often indicates hallucination issues.
-
Time to First Token (TTFT): This measures how quickly your LLM starts typing out its response. Faster responses generally mean happier users, so it's important—though speeding things up too much might sacrifice detail or completeness.
TTFT encompasses retrieval latency, context preparation, and model initialization. Enterprise systems should target under 2 seconds for simple queries. Monitor P95 and P99 percentiles, not just averages, since tail latencies determine user experience.
-
Hallucination Rate: Models love to make stuff up. Tracking how often this happens helps you gauge reliability. Unfortunately, accurately catching hallucinations usually involves manual checks or secondary AI-based validation, making it tough to scale perfectly.
Hallucinations include contradicting sources, adding unsupported information, or wrong attributions. Detection methods include consistency checking, entailment verification with NLI models, and specialized classifiers trained on faithful vs. hallucinated examples.
End-to-End Metrics
In practice, you'll blend retrieval and generation metrics to get a complete picture:
-
Human-in-the-loop Evaluation: Real people review answers for accuracy and completeness. Great for quality, tough on resources.
Effective human evaluation requires careful design: clear rubrics, evaluator training, and smart sampling strategies. Comparative ranking often works better than absolute scoring. Track inter-annotator agreement to ensure consistency and identify areas needing clearer guidelines.
-
A/B Testing: Probably the best real-world validation approach—roll out slightly different versions of your system to see what users prefer. Metrics like Session Depth (how many follow-up interactions happen in a session) or Escalation Rate (how often users bail out to ask humans) tell you a lot about real user satisfaction.
Successful A/B tests require proper experimental design, sufficient runtime (2-4 weeks), and clear success criteria. Track both primary metrics (user satisfaction) and secondary metrics (system performance) to understand trade-offs.
-
User Satisfaction Surveys: Direct feedback through ratings, surveys, or comments provides insights that behavioral metrics miss. Balance survey comprehensiveness with response burden—brief ratings get higher participation.
Ultimately, a solid evaluation strategy mixes automated and human-led approaches. You continuously track quick, easy metrics like Recall@K and latency, while occasionally doing deeper manual evaluations and regular A/B tests. Done right, this combination ensures your RAG system actually delivers relevant, accurate answers that users genuinely trust and find useful.
Infrastructure Concerns
When you’re designing a RAG system in an interview, infrastructure isn’t just a footnote—it often becomes the heart of your discussion. Interviewers love seeing how you handle practical stuff like scaling, reliability, and cost without getting lost in buzzwords.
Scalability
Your system needs to handle lots of users and tons of documents gracefully. How do you make that happen?
-
Horizontal Scaling: Keep your services stateless, so when traffic spikes, you just add more instances. Easy scalability, fewer headaches.
-
Vector Database Scaling: The retrieval part relies on your vector database holding potentially millions of document embeddings. Choosing something that scales well (think Pinecone or Milvus) keeps retrieval fast as your document set grows.
Latency and Throughput
Nobody likes waiting around for answers. Good infrastructure keeps things snappy:
-
Embedding Computation: Embedding models (especially big ones like text-embedding-3-large) need GPUs to run fast. Consider GPU clusters or serverless GPU providers to avoid bottlenecks.
-
Caching Strategies: Cache embeddings and frequently asked questions. Why recompute or retrieve things that rarely change? A good cache can cut latency from hundreds of milliseconds to basically instant.
-
Load Balancing: A reliable load balancer evenly spreads out requests across your services. It prevents traffic jams, keeping things smooth for users.
Reliability and Fault Tolerance
Your system needs to stay up even when things inevitably break:
-
Redundancy: Don’t rely on a single instance of anything critical. If one goes down, others pick up the slack without users noticing.
-
Failover Mechanisms: Set up automatic failover so when a server or service hiccups, another smoothly takes over without downtime.
-
Health Monitoring and Alerts: Track everything important (latency, errors, resource usage) and set up alerts. That way, if something looks off, you’ll know immediately.
Data Security and Compliance
You’re handling sensitive documents—so data security isn’t optional:
-
Access Controls: Authenticate users properly and enforce permissions to ensure people only see what they're supposed to.
-
Data Encryption: Encrypt documents and embeddings everywhere—when stored, and when in transit. This keeps sensitive information safe from prying eyes.
-
Auditing and Logging: Keep logs of who accessed what, when, and why. Crucial if something goes wrong or if you ever face compliance questions.
Cost Management
Costs can balloon quickly—smart design keeps them under control:
-
Resource Optimization: Regularly review your infrastructure to ensure you're using cost-effective instance types, and take advantage of reserved or spot instances for predictable workloads.
-
Embedding Quantization and Compression: Compress your embeddings. By quantizing embeddings from 32-bit to 8-bit integers, you drastically cut storage costs without a big quality hit.
Bottom line, infrastructure concerns aren’t flashy, but they’re a huge part of making a RAG system actually work in the real world. Clearly addressing scalability, reliability, security, and cost in your interview shows that you’re not just about cool tech ideas—you genuinely understand what it takes to build something practical and effective.