What is Gradient Accumulation? How does it work?
Training Transformers requires saving several pieces of state in memory: model weights, model gradients, optimizer states, and activations (required for gradient calculations). Of these components, research shows that the total memory required for the activations scales linearly with the batch size and quadratically with the sequence length. Thus, for large inputs (a.k.a large batch-sizes or sequences), activations become the dominant memory burden.
Gradient Accumulation
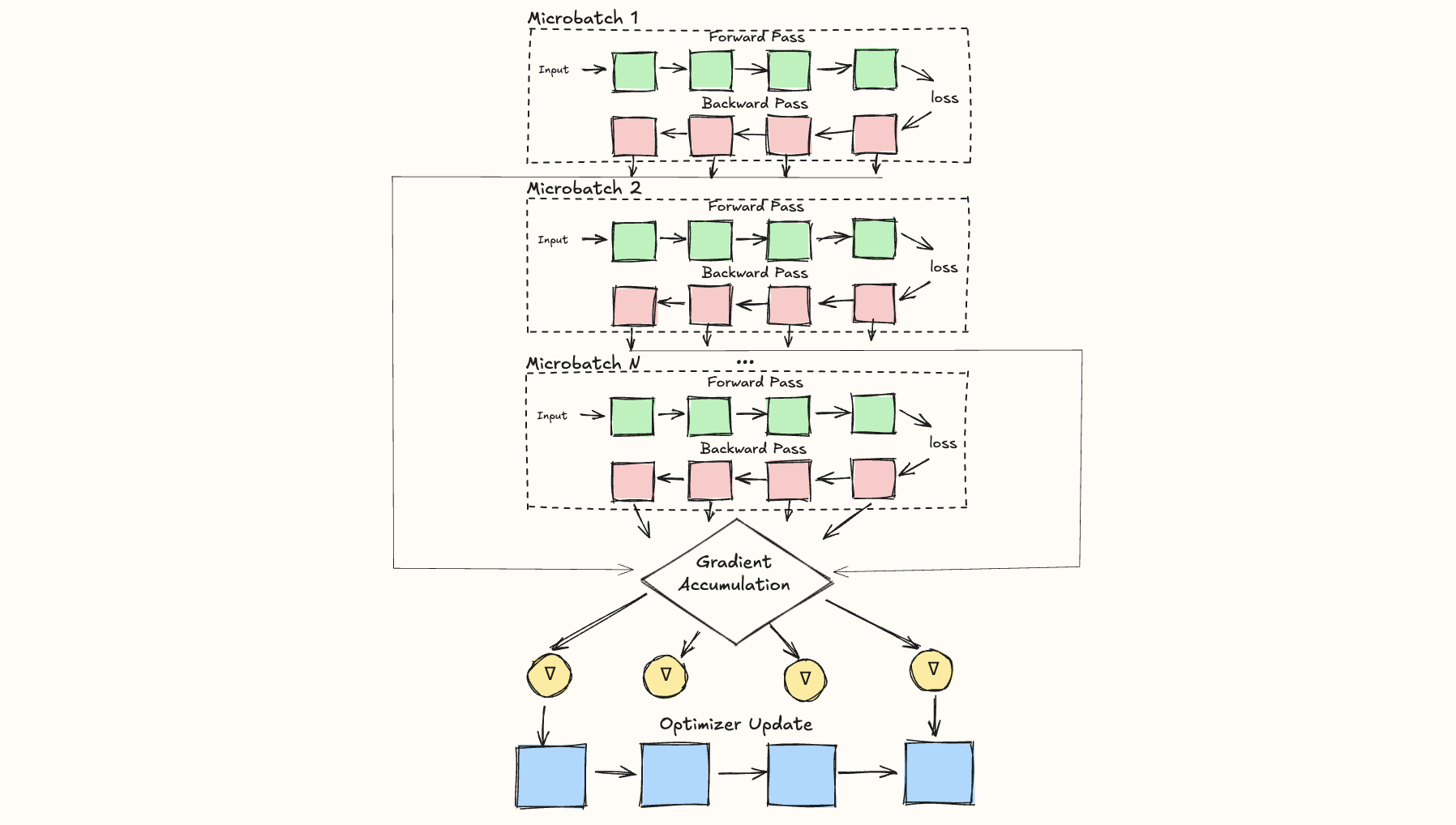
Gradient Accumulation is a technique to prevent this memory explosion. Namely, we split out batches into micro-batches and then, on each micro-batch, one after another, we perform the forward and backward passes, compute the gradients, and then sum the gradients of all the micro-batches together.
Tip
This summing of the micro-batch gradients is where the name, gradient accumulation, comes from, though in practice this accumulation is usually actually an average, to keep the result independent of the number of gradient accumulation steps.
Once the gradients have been accumulated, we perform the optimizer step.
Visually, the process looks like this, performing multiple, successive forward and backward passes (one for each micro-batch) before accumulating the gradients prior to our optimizer step update:
The Downside
Although gradient accumulation allows us to reduce the memory of activations by splitting our batches into micro batches, it does so by computing multiple consecutive forward/backward passes per optimization step, increasing our training time and compute overhead.
For this reason, in distributed training settings, Data Parallelism is used instead. This is because the two are basically the same thing, just that data parallel trains in parallel across multiple compute nodes (instead of in succession across multiple micro-batches) is used instead.