Describe common collective operations on GPUs
GPU Collective operations are distributed patterns for communication and synchronization of the weights, gradients, and data between some set of independent nodes (usually GPUs but can be CPU cores or other compute nodes as well) used in whatever your training setup looks like.
Each one of these nodes is in charge of performing some computation. Then, the convern of the GPU collective operations we'll discuss below is simple:
How do we communicate the result (or some parts of it) to the other nodes for the next computation step?
There are several core operations to achieve this, which we'll discuss in turn below. Note that first three techniques, Broadcast, Gather, and AllGather allow for distributing data among nodes without modification, while the final four, Reduce, AllReduce, Scatter, and AllScatter, allow for distrubuting data across nodes with modification.
Broadcast
The broadcast operation is used in the situation where we have data on a particular node, say Node B, that we'd like to share with all of the other nodes so they can use it for compuation:
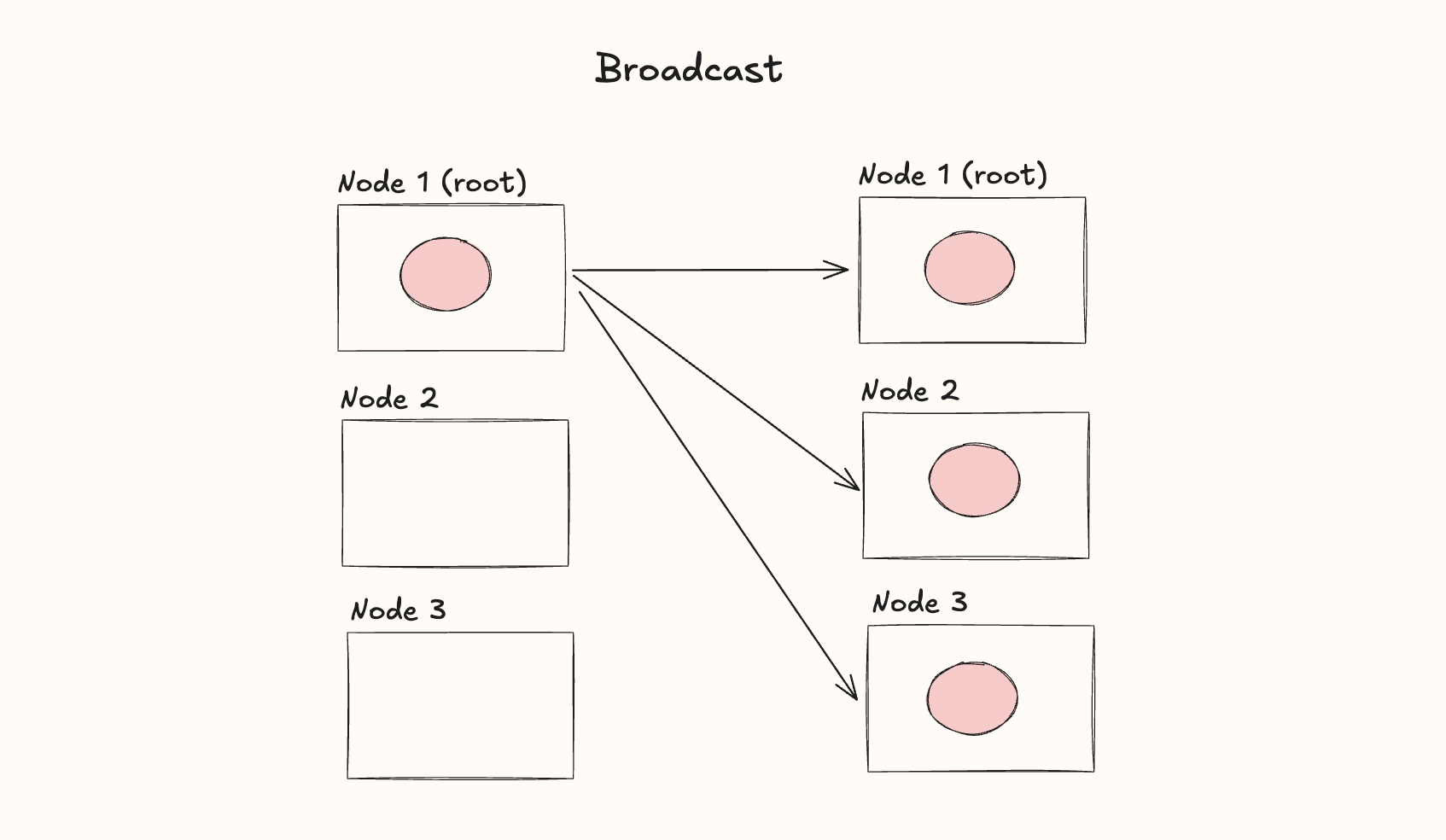
PyTorch's torch.distributed provides a native broadcast method:
import torch
import torch.distributed as dist
def example_broadcast():
tensor = torch.zeros(5, dtype=torch.float32).cuda()
if dist.get_rank() == 0:
tensor = torch.tensor([1, 2, 3, 4, 5], dtype=torch.float32).cuda()
dist.broadcast(tensor, src=0)
print(f"Rank {dist.get_rank()}: {tensor}")
Gather
The gather operation is used when each node has an individual chunk of data and we want to gather all of it onto a single node:
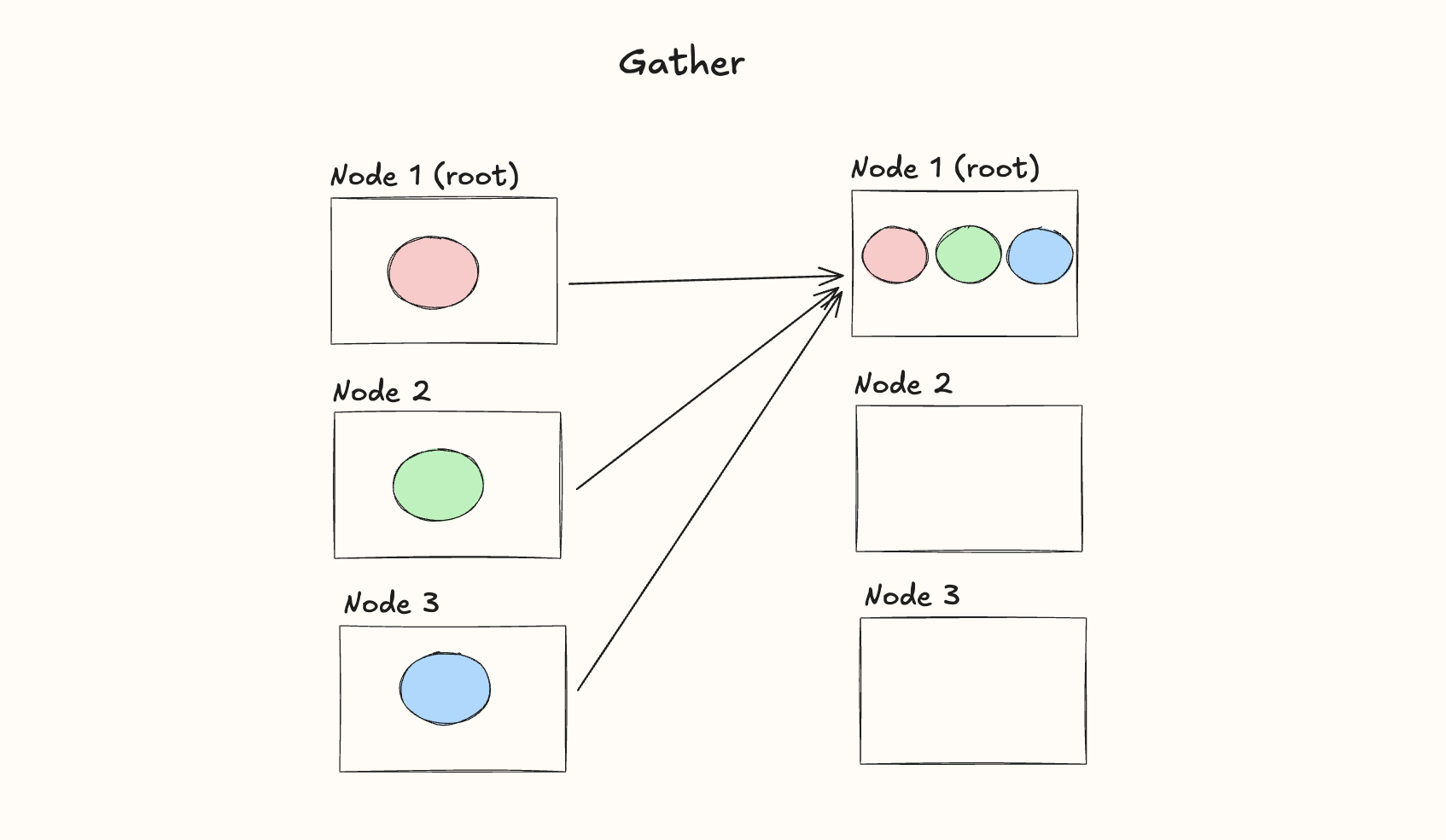
Of course, the data from Node B doesn't actually move, since it was already on Node B to begin with.
As with broadcast above, PyTorch's torch.distributed provides a native gather method:
def example_gather():
tensor = torch.tensor([dist.get_rank() + 1] * 5, dtype=torch.float32).cuda()
gather_list = [torch.zeros(5, dtype=torch.float32).cuda() for _ in range(3)] if dist.get_rank() == 0 else None
dist.gather(tensor, gather_list, dst=0)
if dist.get_rank() == 0:
print(f"Gathered tensors: {gather_list}")
AllGather
The AllGather operation is used when each node has an individual chunk of data and we want to gather all of it to all the nodes:
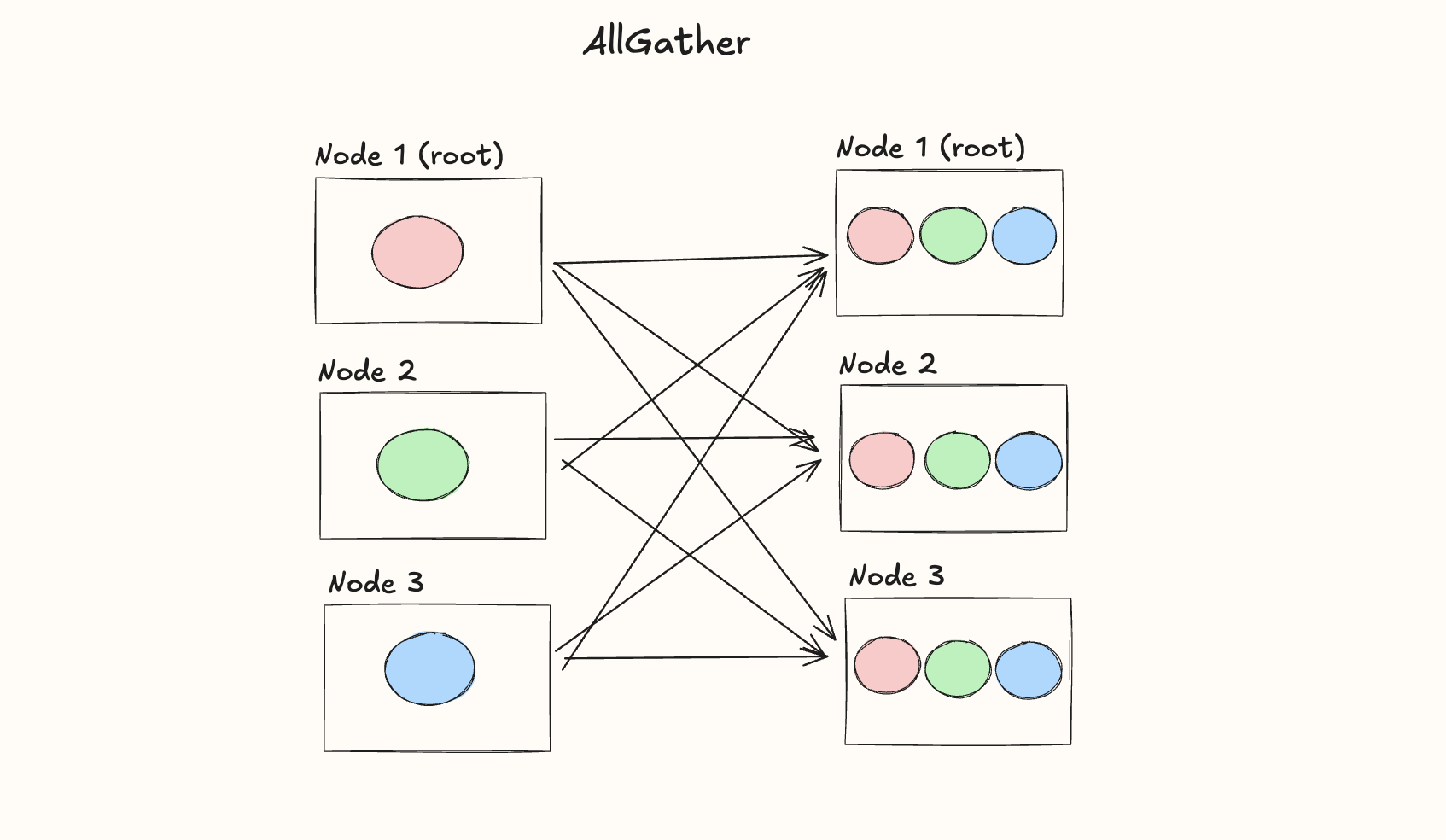
Again, data copied from one node to itself isn't actually copied, since it's already there.
As expected (given the above two examples), PyTorch's torch.distributed provides a native all_gather method:
def example_all_gather():
tensor = torch.tensor([dist.get_rank() + 1] * 5, dtype=torch.float32).cuda()
gather_list = [torch.zeros(5, dtype=torch.float32).cuda() for _ in range(3)]
dist.all_gather(gather_list, tensor)
print(f"Rank {dist.get_rank()}: {gather_list}")
Reduce
The Reduce operator is used when you want to combine data from each node through some function, , and then send it back to the root node. For example, maybe you want to sum or average the loss across each node, and sync that sum back to the root node.
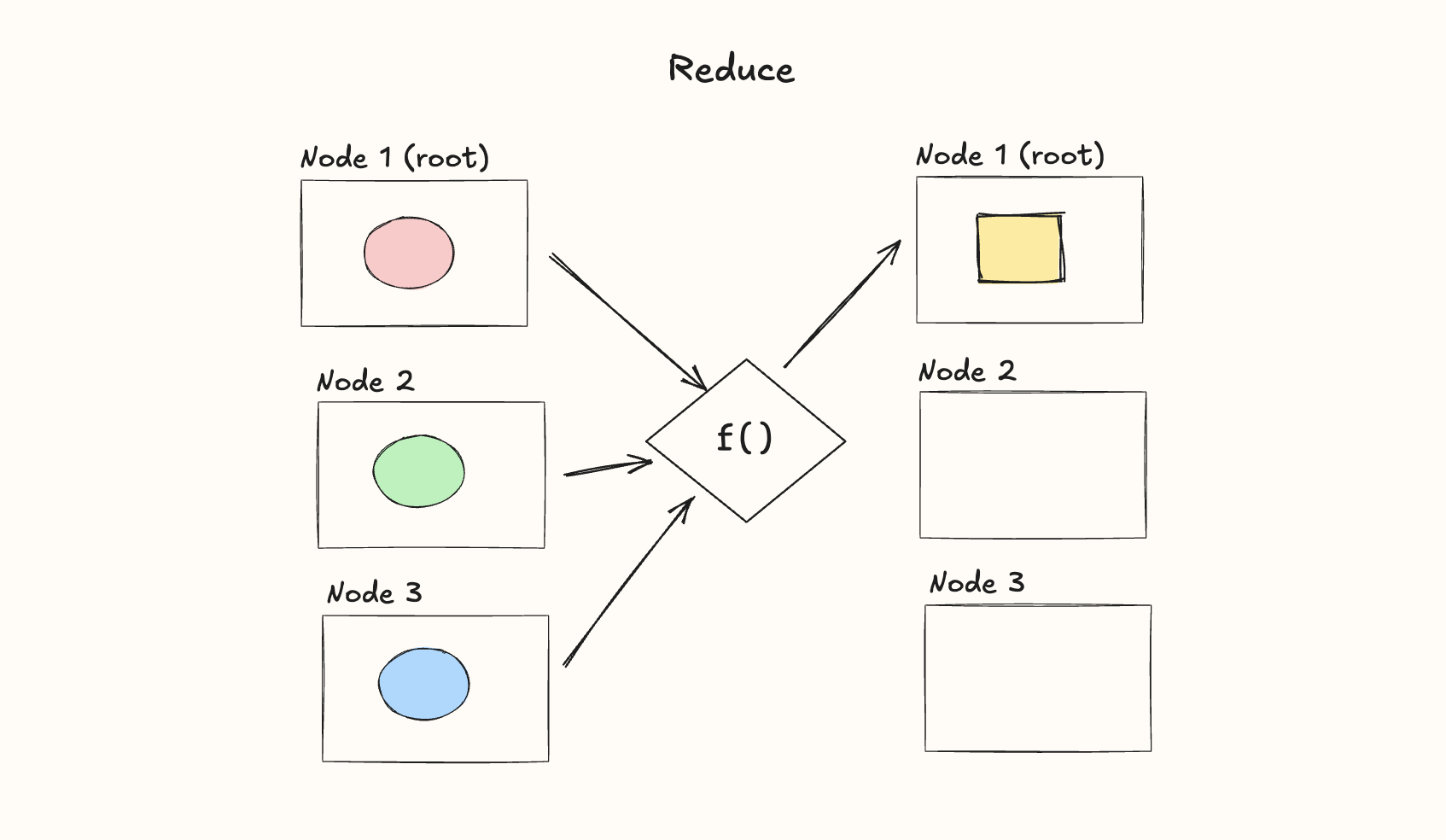
In PyTorch:
def example_reduce():
tensor = torch.tensor([dist.get_rank() + 1] * 5, dtype=torch.float32).cuda()
dist.reduce(tensor, dst=0, op=dist.ReduceOp.SUM)
if dist.get_rank() == 0:
print(f"Reduced tensor: {tensor}")
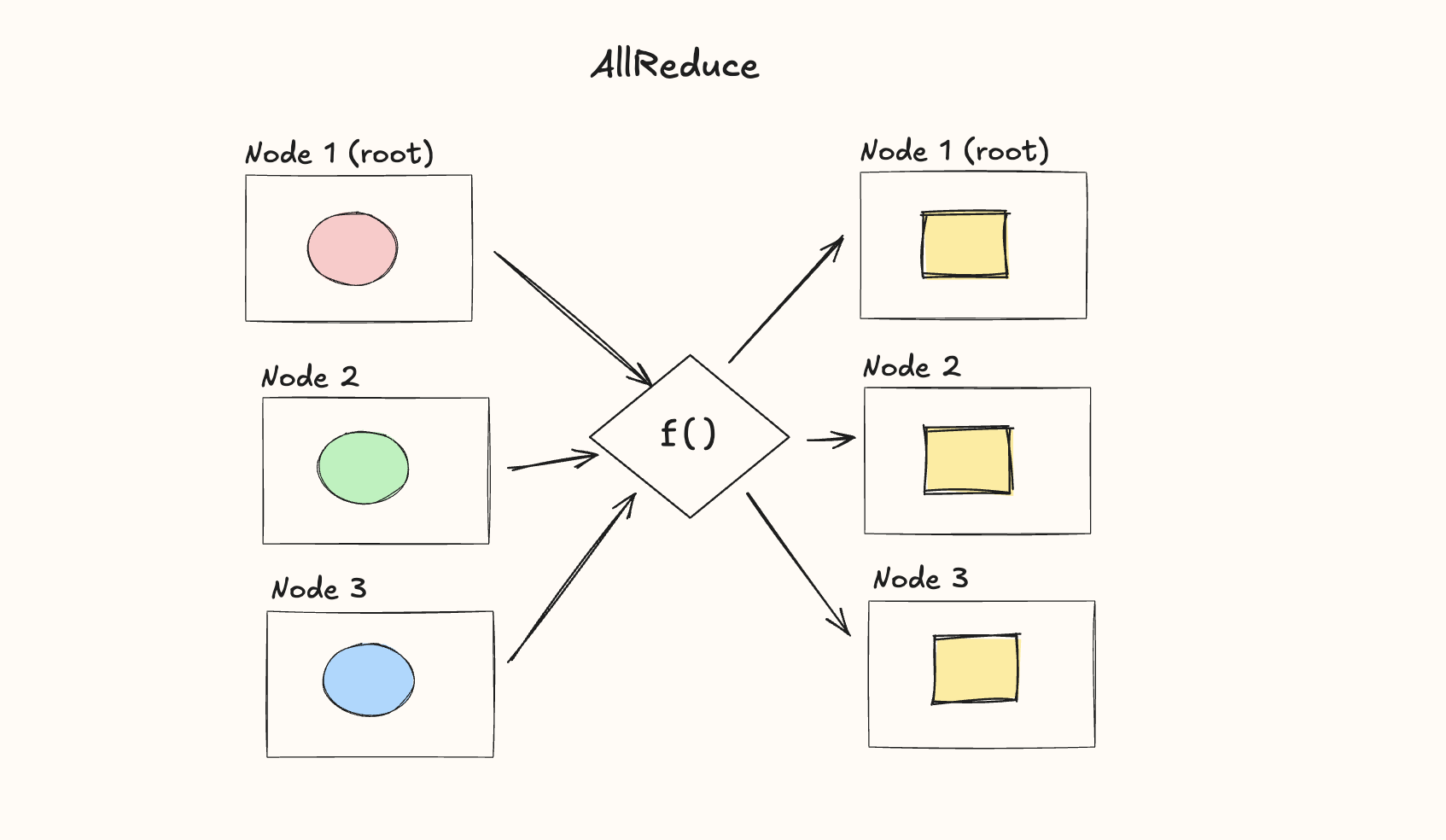
AllReduce
The AllReduce operator is the same as Reduce, but we combine data from each node through some function, , and then send it to all the nodes:
In PyTorch, simply don't specify a destination node:
def example_all_reduce():
tensor = torch.tensor([dist.get_rank() + 1] * 5, dtype=torch.float32).cuda()
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
print(f"Rank {dist.get_rank()}: {tensor}")
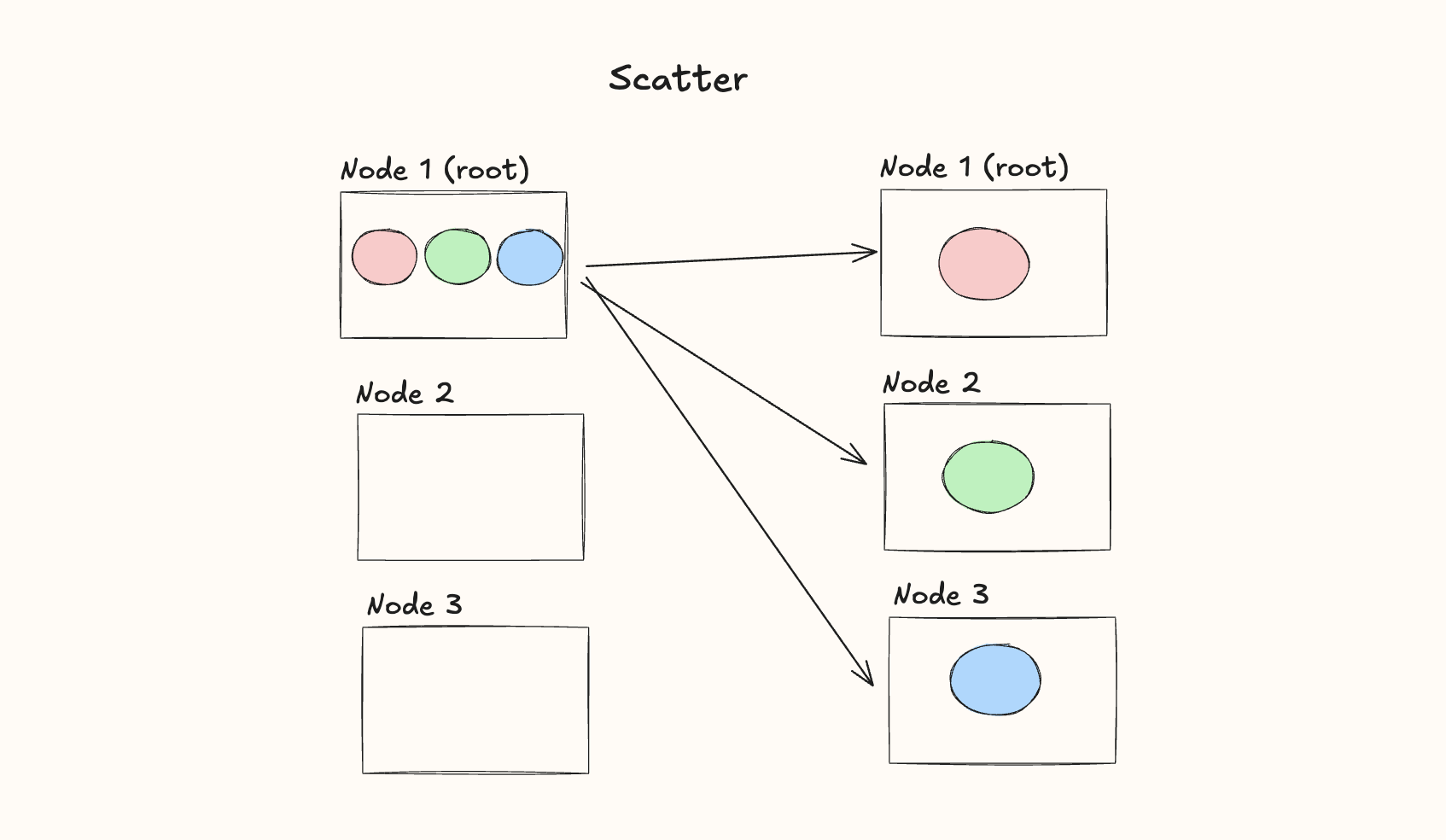
Scatter
The Scatter operator is used when we want to take data from one noe and distribute chunks of it to all the other nodes.
In PyTorch:
def example_scatter():
tensor = torch.zeros(5, dtype=torch.float32).cuda()
if dist.get_rank() == 0:
scatter_list = [torch.tensor([i + 1] * 5, dtype=torch.float32).cuda() for i in range(3)]
else:
scatter_list = None
dist.scatter(tensor, scatter_list, src=0)
print(f"Rank {dist.get_rank()}: {tensor}")
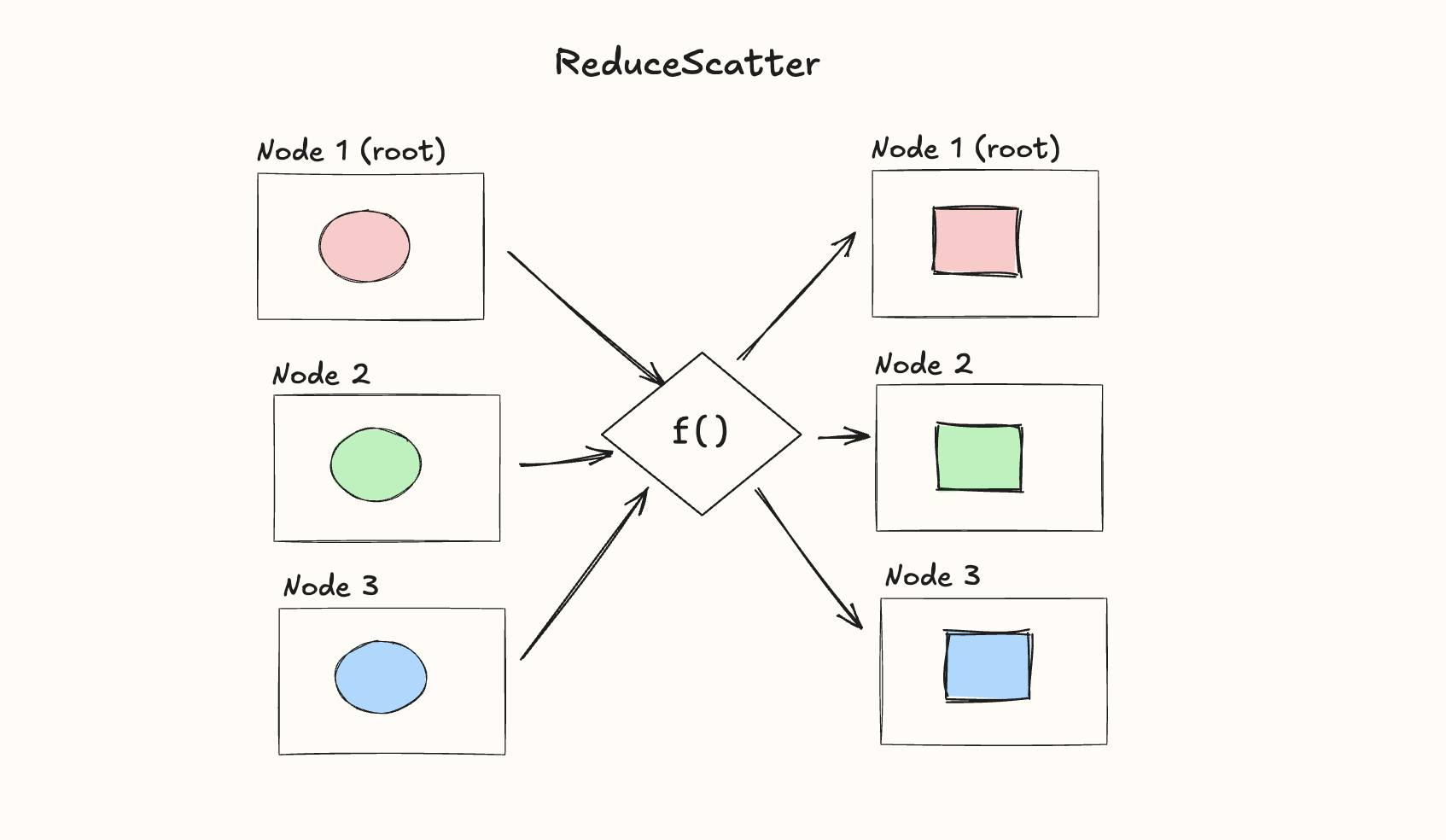
ReduceScatter
The ReduceScatter operation is used when we want to apply an operation like in the Reduce case but instead of moving the result to just one node we also distribute it evenly to all nodes:
In PyTorch:
def example_reduce_scatter():
rank = dist.get_rank()
input_tensor = [
torch.tensor([(rank + 1) * i for i in range(1, 3)], dtype=torch.float32).cuda()**(j+1)
for j in range(3)
]
output_tensor = torch.zeros(2, dtype=torch.float32).cuda()
dist.reduce_scatter(output_tensor, input_tensor, op=dist.ReduceOp.SUM)
print(f"Rank {rank}: {output_tensor}")
These are the core collective operations for GPU communication, though others exist. Check out the PyTorch distributed docs to learn more.